
Des chiffres, des chiffres, toujours des chiffres ? Eh non, pas que ! La science des données passe également par l’analyse de contenus textuels : une spécialisation appelée « fouille de texte » (si vous êtes d’humeur franco-française), mais plus connue sous le nom de « text-mining ».
Aujourd’hui, premier volet de notre série de billets sur le text-mining.
Sommaire
Le text-mining, qu’est-ce que c’est ?
Discipline liée au data mining (vous l’auriez deviné), le text-mining regroupe l’ensemble des méthodes qui permettent d’analyser un texte avec des méthodes statistiques. L’objectif ? Faire émerger du sens d’une suite de mots : livres, discours, tweets… Et tout commence par « quels sont les mots le plus utilisés », pour se diriger, à terme, vers des questions bien plus complexes.
Car oui, vaste sujet que celui du text-mining : on entre par la porte de l’analyse fréquentielle, et l’on navigue jusqu’à l’intelligence artificielle. Cependant, puisqu’il faut bien commencer quelque part, commençons par une introduction au text-mining avec R. Dans ce billet, nous vous présenterons deux méthodes : la méthode « classique », avec le package tm, et la méthode du tidy text-mining, inspirée des travaux d’Hadley Wickham (eh oui, encore lui !).
Première étape, donc : installer les packages, et trouver un texte à fouiller. Pour notre corpus, nous utiliserons le package gutenbergr, qui permet de télécharger le contenu d’un livre accessible sur le Projet Gutenberg. Penchons-nous, à tout hasard, sur le livre : « The philosophy of mathematics« .
install.packages(c("tm", "tidytext", "gutenbergr"))
lapply(X = c("tm", "tidytext", "gutenbergr", "magrittr", "ggplot2", "dplyr"), FUN =library, character.only = TRUE)
book <- gutenberg_works(title == "The philosophy of mathematics")$gutenberg_id %>%
gutenberg_download() %>%
gutenberg_strip()
Text-mining, la méthode « classique »
Pourquoi parle-t-on de méthode classique ? C’est très simple : parce que tm est le package de text-mining historique : sa première version a été publiée sur le CRAN le 13 janvier 2007… il y a donc dix ans. tidytext, de son côté, date d’avril 2016.
Nous l’avions dit plus haut, ce billet se concentrera sur la première étape du text-mining : analyser la fréquence d’apparition des mots dans notre ouvrage. Un processus qui demande une première phase de transformation des données :
– d’abord en transformant notre texte en corpus,
– en le débarrassant du superflu grâce à la fonction tm_map,
– en transformant notre corpus en Term-Document Matrix,
– puis enfin en data.frame.
booktm <- book %>%
#Transformer en corpus
VectorSource() %>%
Corpus() %>%
#Nettoyer le corpus
tm_map(content_transformer(tolower)) %>%
tm_map(stripWhitespace) %>%
tm_map(removeNumbers) %>%
tm_map(removePunctuation) %>%
tm_map(removeWords, stopwords("english")) %>%
#Transformer en matrice
TermDocumentMatrix() %>%
as.data.frame.matrix() %>%
mutate(name = row.names(.)) %>%
arrange(desc(`1`))
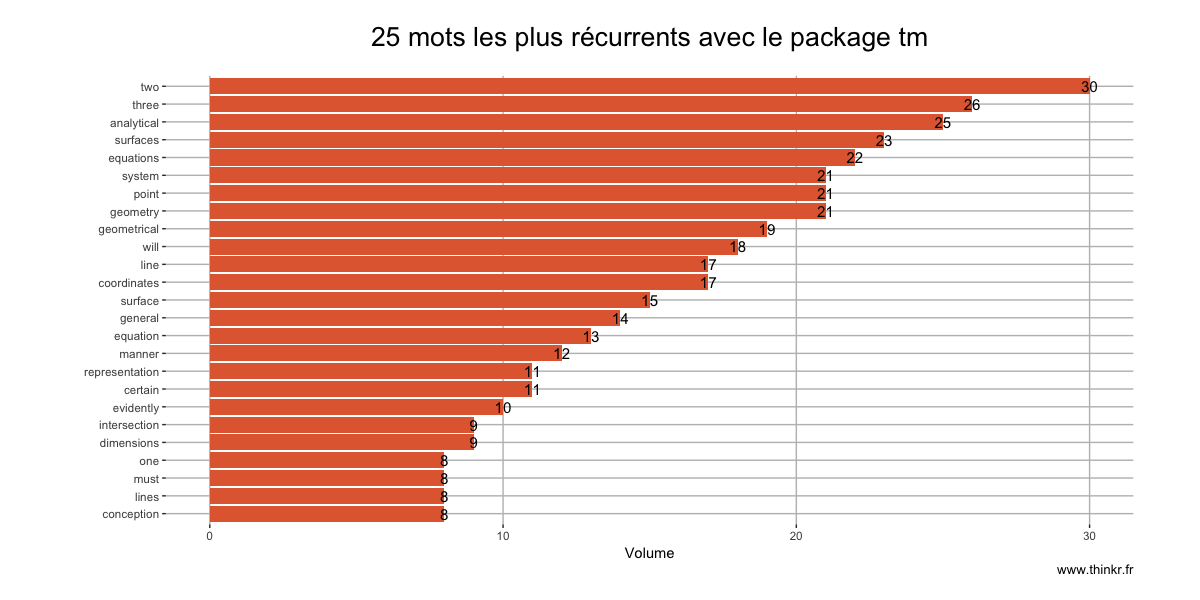
Nous voici donc avec un premier data.frame contenant une liste de fréquence d’apparition des mots dans le texte. Ce qui donne, si nous le visualisons avec ggplot :
tkrtheme <- theme(plot.title=element_text(margin=margin(0,0,20,0), size=20, hjust = 0.5),
plot.subtitle = element_text(margin=margin(0,0,20,0), size = 15, hjust = 0.5),
panel.background = element_rect(fill = "white"),
panel.grid.major = element_line(colour = "grey"),
plot.margin = margin(20,50,20,50))
capt <- "www.thinkr.fr"
ggplot(booktm[1:25,], aes(reorder(name, `1`), `1`)) +
geom_bar(stat = "identity", fill = "#E3693E") +
geom_text(aes(label= as.character(`1`)), check_overlap = TRUE, size = 4) +
coord_flip() +
xlab(" ") +
ylab("Volume") +
labs(title = "25 mots les plus récurrents avec le package tm",
caption = capt) +
tkrtheme
Tidy text-mining
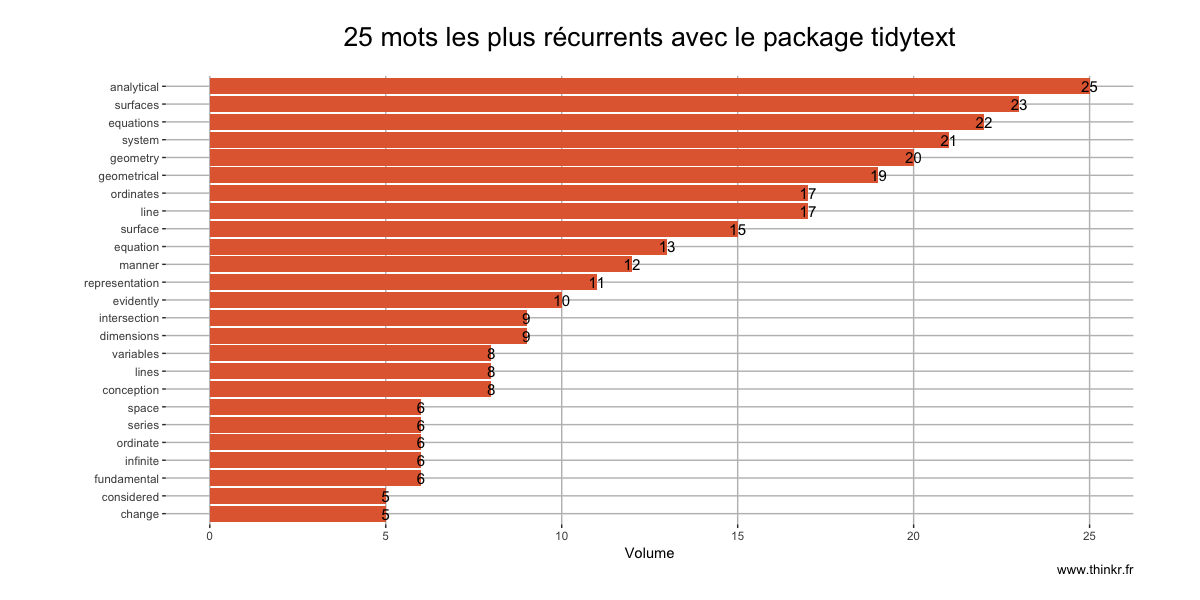
Approche plus récente popularisée par Julia Silge et David Robinson, la méthode du tidy text-mining étend la philosophie des tidy data d'Hadley Wickham, et l'applique à l'analyse textuelle. Voici donc la version "new school" de l'analyse de fréquence d'un texte :
#Pour commencer, créeons un data_frame
tidytext <- data_frame(line = 1:nrow(book), text = book$text)
#Analyse de fréquence
tidytext <- tidytext %>%
unnest_tokens(word, text) %>%
anti_join(stop_words) %>%
count(word, sort = TRUE)
ggplot(tidytext[1:25,], aes(reorder(word, n), n)) +
geom_bar(stat = "identity", fill = "#E3693E") +
geom_text(aes(label= as.character(n)), check_overlap = TRUE, size = 4) +
coord_flip() +
xlab(" ") +
ylab("Volume") +
labs(title = "25 mots les plus récurrents avec le package tidytext",
caption = capt) +
tkrtheme
Comment choisir ?
Bonne question... Et sur ce point, vous vous confronterez à deux écoles : celle des adeptes/habitués des méthodes classiques, et l'école de l'ordocosme. Si l'on s'attarde sur les résultats, on constate également une différence de volume : le nettoyage par le package tm conserve 517 unités, là où tidytext en conserve 407... ce qui n'est pas sans changer le contenu des 25 mots les plus récurrents : on remarque par exemple que tm conserve two et three, là où ils disparaissent avec notre seconde méthode. Un paramètre qui dépend notamment de la liste de "mots-vides" contenue dans chaque package.
Le point fort de la méthode tidytext ? Tout d'abord : beaucoup moins de lignes de code. Ensuite, un package qui a été pensé pour fonctionner avec tous les autres outils du tidyverse, notamment tidyr et dplyr. Maintenant, ne vous reste qu'à choisir votre camps... et peut-être que nos prochains billets vous aideront à trancher 😉 !



[…] un package croisant lui aussi NLP et philosophie tidyverse. Mais vous le connaissiez, on vous en a déjà parlé […]
[…] avec une méthode basique d’analyse fréquentiste, en comparant {tidytext} et {tm} dans notre premier billet. Nous avons poursuivi avec les n-grammes dans notre second numéro. Suite des hostilités […]