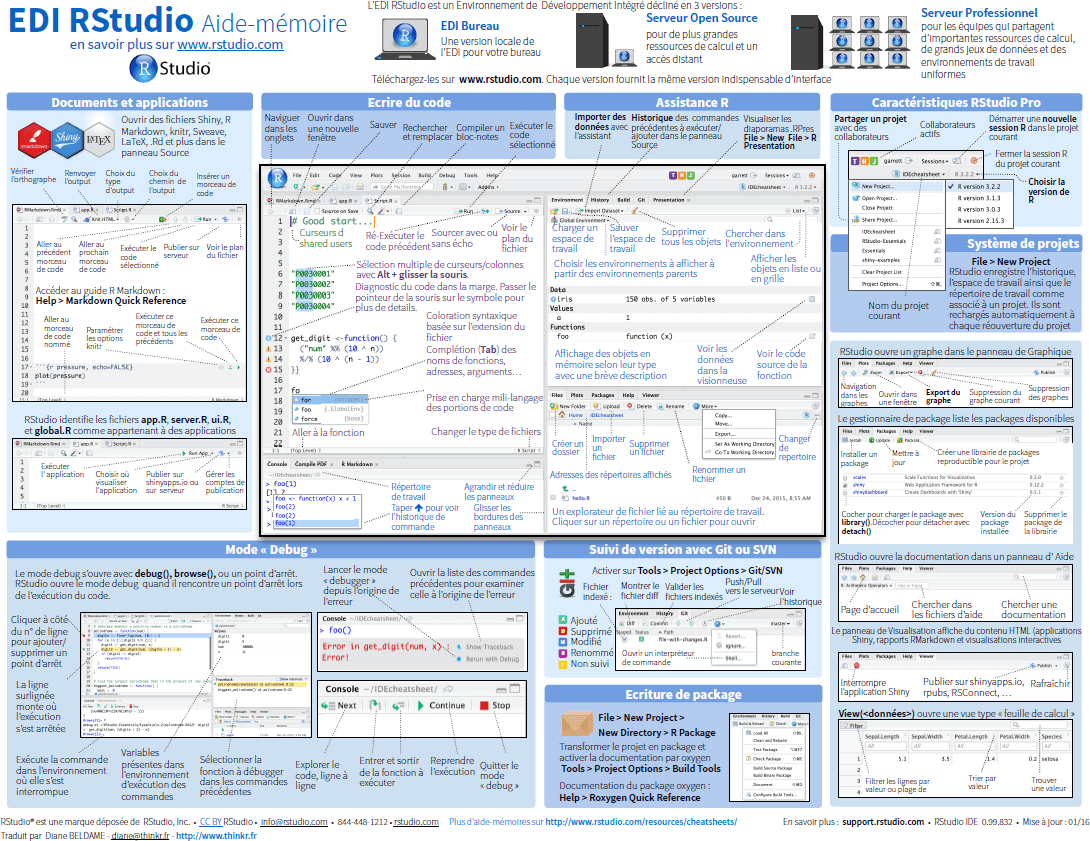
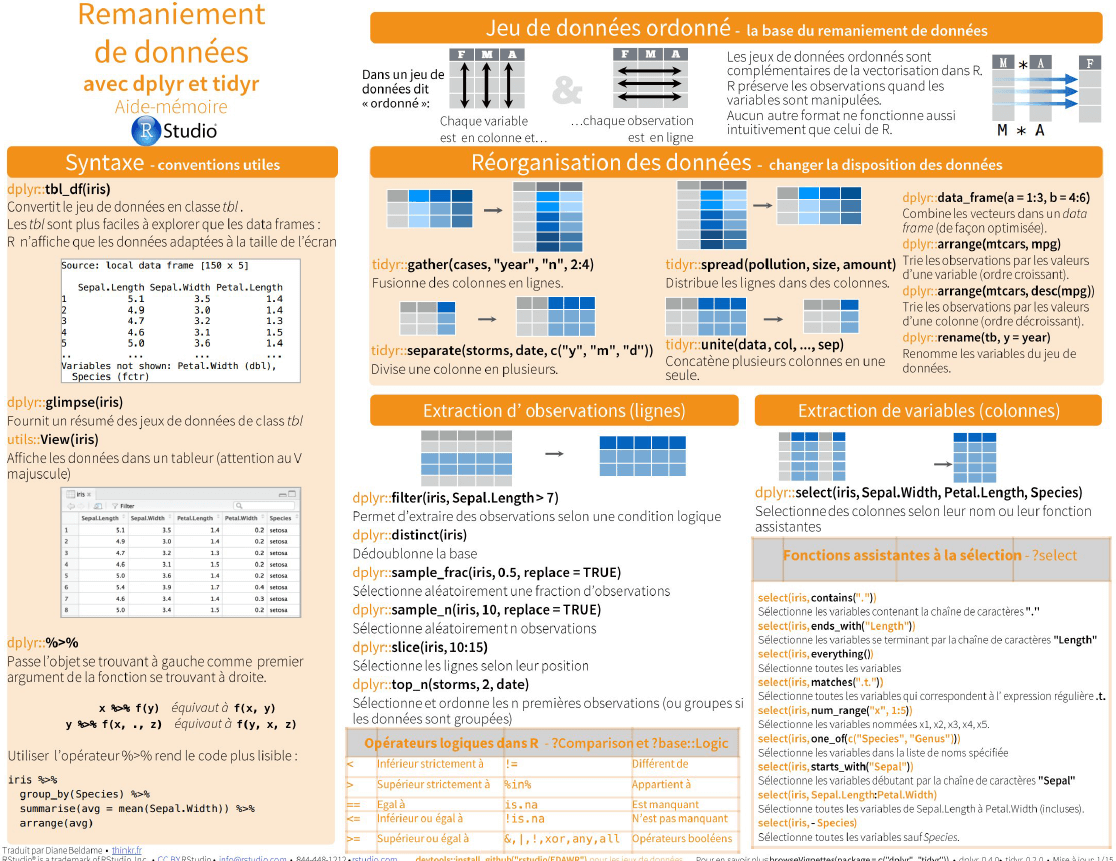
2016-11-09 / Colin Fay / Actualités
Guide de survie ggplot2 à destination des datajournalistes (et des autres aussi)
Lors de son intervention récente à useR! 2016, Andrew Flowers de FiveThirtyEight, plateforme de datajournalisme, chantait les louanges de ggplot2, un package incontournable dans son quotidien. Vous vous en doutiez, nous partageons à 200% son amour pour ce puissant package du tidyverse — ou de l’ordocosme, pour les français. C’est pourquoi nous avons décidé aujourd’hui de vous offrir un guide de ...