
Poursuite de nos bonnes résolutions prises à Bruxelles, avec un parcours en bonne et due forme du package de webscraping rvest.
Sommaire
Commençons par le commencement
Eh oui, il ne faut jamais oublier que la première étape est toujours l’installation. Car rvest ne vient pas nativement avec R, puisqu’il s’agit d’un package additionnel développé par (on vous le donne dans le mille) Hadley Wickham.
# Pour la version stable
install.packages("rvest")
# et pour la version en développement :
devtools::install_github("hadley/rvest")
rvest, pour quoi faire ?
Très bonne question, lecteur. rvest est un package qui vous permet de parser (autrement dit de parcourir et d’aller chercher) le contenu d’une page web, pour le rendre exploitable par R. Un exemple ? Créer une liste depuis une page Wikipédia, récupérer un texte sur une page, transformer un tableau html en data.frame… bref, les possibilités sont nombreuses.
Bon, mettons directement les mains dans le cambouis : comment créer un vecteur avec une chaîne de caractères contenant un texte brut, celui de The Art of War de Tsun Zu, disponible sur le projet Gutenberg ?
Une méthode un peu… bourrin
On pourrait commencer par une méthode old school, en {base}.
text_base <- readLines("http://www.gutenberg.org/cache/epub/132/pg132.html")
Nous voilà avec un joli petit vecteur de 7209 éléments contenant tout le détail html de la page, c'est-à-dire accompagné de son header, et tutti quanti. (si vous avez besoin de vous rafraîchir la mémoire sur le squelette d'une page web, rendez-vous ici). Autant dire, un paquet d'éléments pas vraiment utiles dans notre cas.
Première étape donc, sélectionner le contenu entre les deux balises <body>.
text_base%20%3C-%20readLines(%22http%3A%2F%2Fwww.gutenberg.org%2Fcache%2Fepub%2F132%2Fpg132.html%22)
Nouvelle étape : le corps. Maintenant, il va falloir se débarrasser de toutes les balises html de notre vecteur. Vous êtes bons en regex ? Parce que là, il va falloir supprimer tous les éléments contenus entre < et`>. Bon, il faut avouer que cette regex est plutôt facile :
text_base <- gsub("<.*>", "", text_base)
Puis, adieu éléments vides :
text_base <- text_base[nchar(text_base) > 0]
Et collons le tout dans un seul vecteur :
text_base <- paste(text_base, sep = "", collapse = "")
Avouons que nous n'avons pas choisi l'exemple le plus compliqué du lot. Notre page html était très simple : elle ne contenait que du texte, et nous voulions tout récupérer. Imaginez maintenant refaire la même avec une page Wikipédia dans laquelle on ne veut récupérer qu'un seul paragraphe...
Nous vous entendons d'ici : "Ça ne serait pas plus simple si nous pouvions faire cela en deux lignes de code ?" Eh bien si, justement, c'est à ça que sert {rvest} !
Avec rvest
library(rvest)
library(tidyverse)
text_rvest <- read_html("http://www.gutenberg.org/cache/epub/132/pg132.html") %>%
html_text()
Eh oui, c'est aussi rapide que ça !
rvest et le HTML/CSS
La première étape, donc, est de lire une page html dans votre session R avec la fonction read_html. Par exemple, la page Wikipedia de la distance de Levenshtein.
dist_lev <- read_html("https://fr.wikipedia.org/wiki/Distance_de_Levenshtein")
Ensuite, vous pourriez être tenté de tout envoyer dans un html_text(). Mauvaise idée : il nous faut d'abord sélectionner le ou les noeud(s) CSS que nous allons extraire du DOM. "CS quoi ? DOM qui ?" Bien, petite digression sur le HTML/CSS.
un DOM
DOM est la contraction de Document Object Model. Il s'agit de la représentation sous forme d'arbre de la structure d'une page web, et chaque point de cet arbre est appelé un noeud.
id et class
Si vous avez séché vos cours de CSS, petit rappel sur ce qu'est une balise id vs une balise class.
- D'abord, leur point commun : les deux se placent au sein d'une balise (par exemple : <p id="plop"></p>). Ces éléments réfèrent à des définitions CSS. Par exemple, ici la définition CSS .plop sera appliqué à ce qui se trouve entre ces deux balises.
- Leurs différences : l'id fait référence à un élément unique dans le DOM, la classe peut être reprise dans plusieurs balises.
-
Côté CSS, l'id s'écrit avec un #, la classe avec un . .
-
Dans le CSS, Vous pouvez faire référence à "tous les paragraphes (balises p) d'une classe ploum" avec
p.ploum.
</digression off>
Parcourir un DOM avec rvest
Pour extraire du texte
C'est sur ces différents éléments que va s'appuyer rvest pour aller chercher des éléments dans votre page web. Par exemple, on pourrait vouloir la liste des titres de niveau 2.
dist_lev %>%
html_nodes("h2") %>%
html_text()
[1] "Sommaire"
[2] "Définition[modifier | modifier le code]"
[3] "Exemples[modifier | modifier le code]"
[4] "Algorithme de Levenshtein[modifier | modifier le code]"
[5] "Exemple de déroulement de l'algorithme[modifier | modifier le code]"
[6] "Généralisation[modifier | modifier le code]"
[7] "Notes et références[modifier | modifier le code]"
[8] "Voir aussi[modifier | modifier le code]"
[9] "Menu de navigation"
Voire, tout simplement, le texte du cinquième élément de la partie Notes et Références :
dist_lev %>%
html_node("#cite_note-5 .reference-text") %>%
html_text()
[1] "An O(NP) Sequence Comparison Algorithm Sun Wu, Udi Manber & Gene Myers."
Vous faites les gros yeux ? Il y a de quoi, et on va vous dire pourquoi : on a sauté une étape ici — comment trouver l'élément "#cite_note-5 .reference-text" ? Pour cela, suivez la recommandation officielle, et installez SelectorGadget, un add-in Chrome pour retrouver le chemin d'un élément dans un DOM en cliquant dessus.
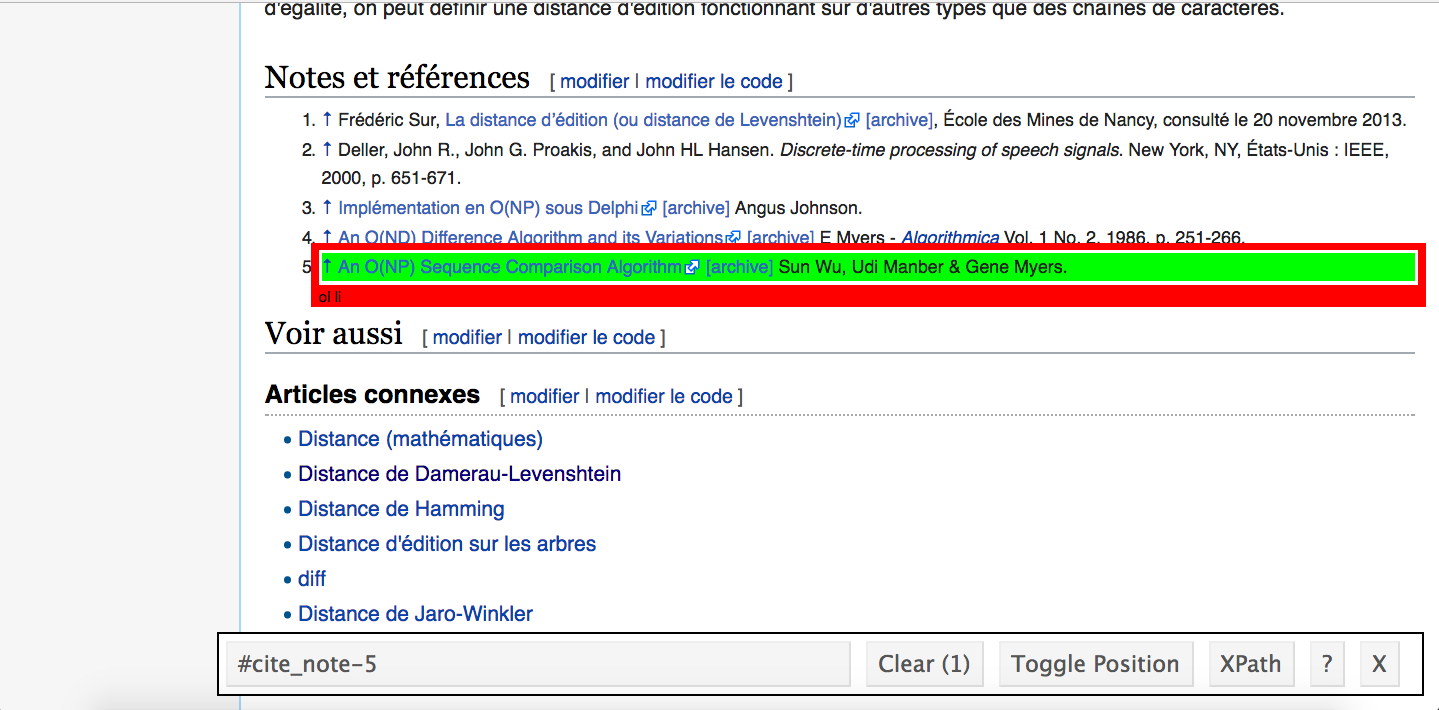
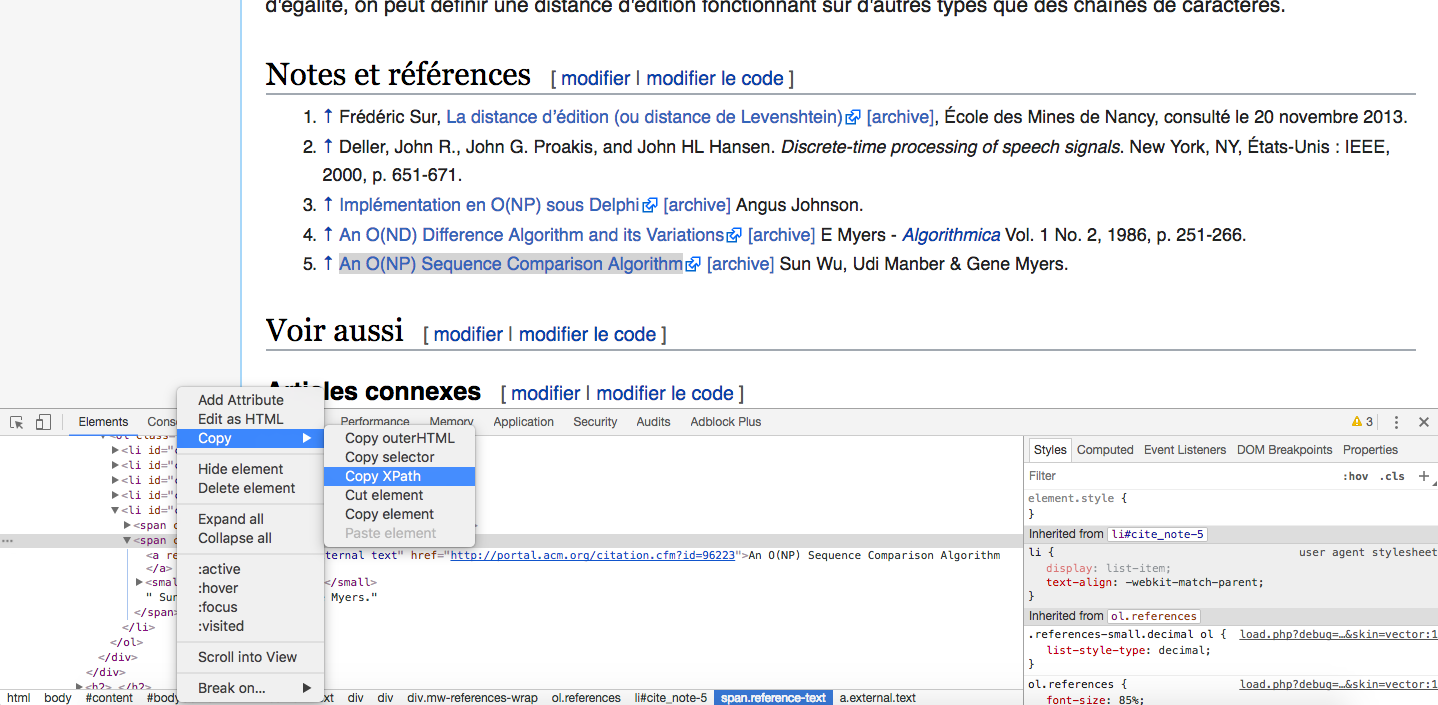
À noter que, si vous êtes un peu plus pointilleux (ou ne souhaitez pas installer de nouvel addin sur votre navigateur), vous pouvez également utiliser le XPATH de votre page HTML. Pour ça, direction votre navigateur (ici toujours Google Chrome). Sur la page, faites un clic droit sur la partie qui vous intéresse, et choisissez Inspecter. La console de développement s'ouvre, et il suffit de choisir l'élément en question dans le code HTML qui s'affiche, puis clic droit > Copy > Copy XPATH.
dist_lev %>%
html_node(xpath = '//*[@id="cite_note-5"]/span[2]') %>%
html_text()
[1] "An O(NP) Sequence Comparison Algorithm Sun Wu, Udi Manber & Gene Myers."
En passant, vous noterez l'utilisation de html_node et html_nodes, renvoyant respectivement le premier élément du DOM, et tous les éléments du DOM. Les mêmes variantes existent pour html_attr et html_table.
Extraire un tableau
La page Wikipedia que nous avons contient des tableaux. Vous savez, ces trucs rédigés en html comme ça :
Prénom
Nom
Profession
Colin
Fay
Data Analyst
Bref, une structure facilement reconnaissable, et potentiellement simple à transformer en tableau. Ça, c'est le job de html_table(), qui prend en entrée la liste des noeuds "table", et transforme en matrice.
dist_lev %>%
html_node('table') %>%
html_table()
C H I E N S
1 0 1 2 3 4 5 6
2 N 1 0 0 0 0 0 0
3 I 2 0 0 0 0 0 0
4 C 3 0 0 0 0 0 0
5 H 4 0 0 0 0 0 0
6 E 5 0 0 0 0 0 0
Voilà, c'est aussi simple que ça !
Travailler avec les attributs
Interlude : tags et attributs
En html, votre balise de gauche (celle qui est entourée de < >) se compose de plusieurs éléments, et notamment le tag et les attributs.
- Le tag est l'élément qui permet de distinguer la place de votre contenu dans l'arbre. Par exemple, le tag
pindique un nouveau paragraphe,h1un titre de niveau 1, etc. Les tags sont universels : n'importe quel navigateur saura lire <h1>Titre</h1>. Ce sont les attributs qui viennent personnaliser ces tags. -
Les attributs sont l'ensemble des éléments qui vont venir enrichir votre tag. Nous avons par exemple vu les id et les class CSS. Ce sont qui vont rendre le tag moins générique, et vous permettre de personnaliser une page : <h1 class = "blueheader">Titre</h1> n'aura de sens qu'accompagné de la feuille CSS définissant
blueheader.
Scraper les tags et les attributs d'un élément du DOM
dist_lev %>%
html_node("h1") %>%
html_attrs()
id class lang
"firstHeading" "firstHeading" "fr"
# Anciennement connu comme html_tag()
dist_lev %>%
html_node(xpath = '//*[@id="mw-content-text"]/div/h2[3]') %>%
html_name()
[1] "h2"
Bon, ici, ce n'est pas très informatif, il faut l'avouer, mais vous avez l'idée 🙂
Faire du webscraping avec rvest
Télécharger tous les datasets sur une page
C'est bien beau tout ça, mais ça ne se révèle pas encore très utile. Vous voulez des idées plus croustillantes ? Nous en avons sous la main : par exemple, comment télécharger tous les .csv contenus sur cette page ?
library(stringr)
dataset_url <- "https://vincentarelbundock.github.io/Rdatasets/datasets.html"
list_dataset <- read_html(dataset_url) %>%
html_nodes(".cellinside:nth-child(6) a") %>%
html_attr("href")
purrr::map(.x = list_dataset,
~download.file(.x,
destfile = str_extract(.x, "[[:alnum:]]*.csv$"))
)
Et voilà !
De la page web au data frame
Essayons quelque chose d'autre. Comment créer un tableau depuis les informations contenues dans une page web ? Comment transformer un trombinoscope (comme celui de ThinKR) en data.frame ?
thinkr_url <- read_html("http://www.thinkr.fr/expert-logiciel-r/")
# Les noms
thinkr_url %>%
html_nodes(".team-author-name") %>%
html_text()
[1] "Vincent Guyader" "Diane Beldame" "Romain François" "Colin Fay"
# Les mails
thinkr_url %>%
html_nodes("a.mail") %>%
html_attr("href") %>%
stringr::str_replace_all("mailto:", "")
[1] "[email protected]" "[email protected]" "[email protected]" "[email protected]"
# Les comptes twitter
thinkr_url %>%
html_nodes("a.twitter") %>%
html_attr("href")
[1] "https://twitter.com/thinkr_fr"
[2] "https://twitter.com/dianebeldame"
[3] "https://twitter.com/romain_francois?lang=fr"
[4] "https://twitter.com/_colinfay"
# Les comptes Github
thinkr_url %>%
html_nodes("a.github") %>%
html_attr("href")
[1] "https://github.com/ThinkRstat/ThinkR" "https://github.com/DianeBeldame"
[3] "https://github.com/romainfrancois" "https://github.com/colinfay"
# Et pour tout avoir dans un joli tableau :
thinkr <- data_frame(
name = thinkr_url %>%
html_nodes(".team-author-name") %>%
html_text(),
mail = thinkr_url %>%
html_nodes("a.mail") %>%
html_attr("href") %>%
stringr::str_replace_all("mailto:", ""),
twitter = thinkr_url %>%
html_nodes("a.twitter") %>%
html_attr("href"),
github = thinkr_url %>%
html_nodes("a.github") %>%
html_attr("href")
)

Facile n'est-il pas ?
rvest avancé
Naviguer sur une page avec rvest
Passons maintenant à une méthode plus avancée : la simulation de navigation. Vous aurez besoin de la fonction html_session, qui mîme le comportement de votre navigateur. Les fonctions complémentaires étant jump_to, simulant le "voyage" vers un lien de la page, follow_link, pour suivre un lien avec un élément css/xpath, ou directement avec le texte du lien, back(), pour un retour en arrière, et session_history, qui vous donne l'historique de la navigation.
En clair :
library(httr)
thinkr_session <- html_session("http://www.thinkr.fr/")
# Avec les urls
thinkr_session %>%
jump_to("formation-au-logiciel-r/") %>%
jump_to("programmation-avancee-avec-r/") %>%
session_history()
Accueil
http://www.thinkr.fr/formation-au-logiciel-r/
- http://www.thinkr.fr/formation-au-logiciel-r/programmation-avancee-avec-r/
# Avec du texte
thinkr_session %>%
follow_link("Développement en langage R") %>%
follow_link("contactez-nous") %>%
session_history()
Accueil
http://www.thinkr.fr/developpement-r/
- http://www.thinkr.fr/contact/
# Avec un css
thinkr_session %>%
follow_link(css = ".entry-title a") %>%
session_history()
Accueil
- http://www.thinkr.fr/au-menu-du-jour-r6-partie-2/
Créer de la donnée en naviguant avec rvest
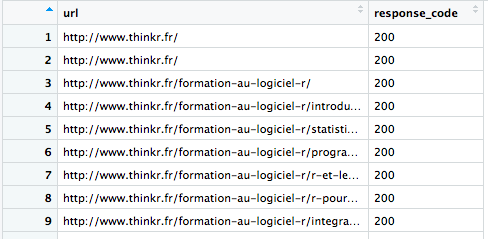
Voilà, combinons maintenant tout ça. Pour un petit coup de main, nous allons faire appel à httr, et créer des web crawlers ultra basiques. Le premier renvoie la liste des liens de la page, et leur statut (200/400, etc.)
library(httr)
get_status <- function(url){
return(data.frame(url = url,
response_code = html_session(url) %>% status_code()))
}
get_status("http://www.thinkr.fr")
url response_code
1 http://www.thinkr.fr 200
get_page_status <- function(url){
# Open a session
url_session <- html_session(url)
list_url <- url_session %>%
html_nodes("a") %>%
html_attr("href")
#Remove anchor
list_url <- list_url[-grep("#.*", list_url)]
# Get all the status
status_link <- purrr::map_df(list_url, get_status)
return(status_link)
}
get_page_status("http://thinkr.fr") %>% View
Le second de nos crawlers choisira un lien de manière aléatoire dans la page que nous lui fournirons, jusqu'à rencontrer une page indisponible qui renvoie un autre code que 200.
crawler <- function(url){
# Open a session
url_session <- html_session(url)
request_code <- url_session %>% status_code()
i <- 1
while(request_code == 200){
url_list <- url_session %>%
html_nodes("a") %>%
html_attr("href")
url_session <- url_session %>% jump_to(sample(url_list, 1))
print(url_session$url)
print(sprintf("Niveau %s",i))
i <- i +1
request_code <- url_session %>% status_code()
}
}
# Testons le sur la page Wikipedia des Web Crawler
crawler("https://en.wikipedia.org/wiki/Web_crawler")
Bien sûr, notre crawler pourrait être beaucoup plus simple : httr nous renvoie une erreur dès qu'il rencontre la moindre erreur http, donc :
crawler_simple <- function(url){
url_session <- html_session(url)
i <- 1
while(TRUE){
url_list <- url_session %>%
html_nodes("a") %>%
html_attr("href")
url_session <- url_session %>% jump_to(sample(url_list, 1))
print(sprintf("Niveau %s",i))
i <- i +1
print(url_session$url)
}
}
crawler_simple("https://en.wikipedia.org/wiki/Web_crawler")

Cliquez sur le gif pour l'ouvrir
Bien sûr, ici, le code reste simple car nous demandons à notre crawler d'imprimer à l'écran jusqu'à manquer d'air. Il faudrait procéder autrement si nous voulions conserver les données ! Mais pour ça, c'est à votre tour 😉


