
Sommaire
Présentation de l’étude INCA3
En décembre dernier, l’agence nationale de sécurité sanitaire de l’alimentation, de l’environnement et du travail (ANSES) diffusait en Open Data les données de son étude INCA3 publiée en 2017.
Vous allez nous dire : Quel rapport entre l’ANSES et la civilisation précolombienne ? Aucun : INCA3, c’est le nom de code donné par l’ANSES à son étude nationale sur les consommations et les habitudes alimentaires des français. INCA pour étude Individuelle Nationale des Consommations Alimentaires, 3 car c’est la troisième étude du genre, réalisée en 2014-2015 (les deux précédentes datant de 1998-1999 et de 2006-2007).
Une étude INCA, quésaco ? Chaque étude INCA a pour finalité de photographier les consommations alimentaires et les habitudes alimentaires de la population française. Mais pourquoi donc ? Pour une raison toute à fait louable : prévenir l’apparition de certaines maladies sur lesquelles l’alimentation joue un rôle essentiel (maladies cardiovasculaires, cancer, etc.). Mais également pour améliorer la qualité nutritionnelle des aliments et garantir leur sécurité sanitaire. En pratique, les résultats des études INCA sont par exemple utilisés comme bases à la construction ou à la modification de nouvelles réglementations, notamment dans le cadre du Programme National Nutrition Santé (PNNS). Petit exemple hypothétique : si une étude INCA démontre que les français mangent de plus en plus de sel, et que cette consommation ne cesse d’augmenter (en comparaison aux études INCA précédentes), alors ce sera peut-être l’occasion de développer ou de renforcer les réglementations relatives au sel. Pour un aperçu des principaux résultats de l’étude INCA3, c’est par ici que ça se passe : dossier de presse.
La diffusion des données brutes d’INCA3 est l’occasion pour nous de nous pencher sur ces données d’utilité publique qui regorgent d’informations. Elles sont d’ailleurs à votre disposition dans le nouveau package made in ThinkR {inca3}. Vous trouverez dans ce package les données brutes (nettoyées au préalable par nos soins) ainsi que de la documentation vous permettant une utilisation des données sans accrocs.
Méthodologie utilisée dans le cadre de l’étude INCA3
 Analyser des données, c’est bien. Mais les analyser en comprenant au préalable comment elles sont été recueillies, c’est mieux ! La méthodologie détaillée de l’étude INCA3 est disponible ici : rapport scientifique. Une présentation générale est également disponible dans le package
Analyser des données, c’est bien. Mais les analyser en comprenant au préalable comment elles sont été recueillies, c’est mieux ! La méthodologie détaillée de l’étude INCA3 est disponible ici : rapport scientifique. Une présentation générale est également disponible dans le package {inca3}. Mais voici un petit aperçu du protocole utilisé dans le cadre d’INCA3 :
Au total, 5 855 personnes —2 698 enfants de 0 à 17 ans et 3 157 adultes de 18 à 79 ans— ont participé à l’étude INCA3 (échantillon représentatif d’individus vivant en France métropolitaine, hors Corse). Cela a nécessité la mise en place d’un terrain d’enquête faramineux : 200 enquêteurs mobilisés, 150 questions posées à chaque personne interrogée.
Chaque personne de l’échantillon a dû enregistrer ses consommations alimentaires pendant 3 jours : elle devait identifier et quantifier tous les aliments et boissons consommés pendant chacune de ces 3 journées.
Parallèlement à ce recueil de consommations alimentaires, la personne devait renseigner des informations complémentaires par le biais de questionnaires supplémentaires. Ces derniers abordaient les thèmes suivants :
- consommation de compléments alimentaires
- état de santé et régimes particuliers
- habitudes et pratiques alimentaires
- activité physique et sédentarité
- caractéristiques socio-économiques et niveau de vie
Chacun de ces questionnaires complémentaires pris indépendamment est une source d’information en soi. L’étude INCA3 est ainsi également le moyen de dresser un état des lieux sur des thématiques variées qui vont au-delà des consommations alimentaires : les usages culinaires, la pratique du sport, l’allaitement, etc.
Des mesures anthropométriques ont également été relevées pour chaque personne interrogée, notamment le poids (en kg) et la taille (en cm).
Présentation des données disponibles dans le package {inca3}
data(package = "inca3")$results[, "Item"]## [1] "actphys_sedent" "actphys_sedent_decode"
## [3] "apports_nut_alim" "apports_nut_alim_decode"
## [5] "conso_ca_indiv" "conso_ca_indiv_decode"
## [7] "conso_ca_prod" "conso_ca_prod_decode"
## [9] "conso_compo_alim" "conso_compo_alim_decode"
## [11] "conso_gpe_inca3" "conso_gpe_inca3_decode"
## [13] "description_indiv" "description_indiv_decode"
## [15] "fpq" "fpq_decode"
## [17] "habitudes_indiv" "habitudes_indiv_decode"
## [19] "habitudes_men" "habitudes_men_decode"
## [21] "liaison_format" "nomenclature"
## [23] "nomenclature_decode" "occasions"
## [25] "occasions_decode" "table_correspondance"Une dizaine de tables de données sont présentes dans le package. Dans leur format “brut”, les valeurs des variables sont codées, et il faut donc utiliser une table de correspondance (également disponible dans le package) pour trouver le libellé exact de chaque valeur. Mais nul besoin de faire cette opération vous-même : nous avons déjà fait la manipulation pour mettre à votre disposition des données aux petits oignons. Vous trouverez ainsi chaque table sous un format “décodé” (_decode), déjà prêt pour l’analyse. Vous trouverez également dans le package une description de toutes les variables disponibles dans chaque table. Bien pratique quand on sait que certaines d’entre elles contiennent plus d’une centaine de variables !
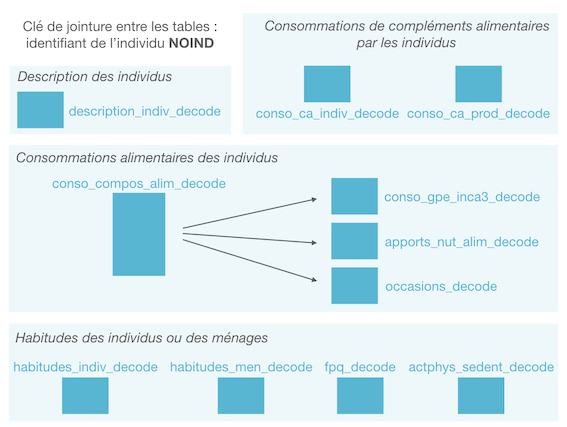
Quoi qu’il en soit, voici un petit aperçu des données disponibles dans {inca3} :
Table descriptive des individus
La table description_indiv_decode contient toutes les informations descriptives collectées sur les individus interrogés. Elle se retrouvera donc bien souvent au cœur des analyses réalisées. Chaque individu y est renseigné sous la forme d’un code NOIND, également renseigné dans toutes les autres tables et qui servira de base à la construction des différentes jointures entre tables.
Cette table contient les différentes variables de pondération. A quoi peuvent-elles bien servir ? On va tout vous expliquer. L’échantillon d’individus interrogés lors de l’étude INCA3 n’est pas représentatif de la population française : la proportion de femmes est peut-être plus importante dans l’échantillon d’INCA3 que dans la population française (c’est un exemple hypothétique) ; ou bien les personnes âgées de 65 ans et plus sont peut-être moins nombreuses qu’attendu. Bien que couramment (si ce n’est toujours) observé lors de la réalisation d’un sondage, ce phénomène est problématique. En effet, si aucune correction n’est effectuée, l’utilisateur qui analyse les données risque de fournir des résultats erronés dans le sens où ils ne correspondent pas à ce que l’on obtiendrait réellement si on interrogeait chaque français. Il faut donc trouver le moyen de corriger de différentiel de proportions pour faire correspondre l’échantillon à la population-mère. C’est ici qu’intervient la méthode de redressement ! Afin de retrouver les proportions attendues, une première approche consisterait à supprimer des individus (et leurs données !) de l’échantillon. Cette solution est frustrante quand on se rappelle de la difficulté de la mise en place d’un terrain d’enquête. Pensons un peu à ces enquêteurs qui ont passé des heures à recueillir ces précieuses données. Une autre solution consiste à redresser l’échantillon par pondération. Cette fois-ci, on conserve toutes les données, mais on attribue à chaque individu un ‘poids’ en fonction de la catégorie à laquelle il appartient. Les individus sur-représentés dans l’échantillon (par rapport à leur représentation dans la population-mère) bénéficieront d’une valeur de pondération faible. Et inversement. Et ce sont ces fameuses valeurs que nous retrouvons dans les variables de pondération de la table description_indiv_decode. Ainsi, à moins de vouloir réaliser des analyses sur l’échantillon en tant que tel, il est primordial d’utiliser les pondérations pour inférer sur la population française.
En outre, sont indiqués dans cette table les renseignements suivants : tranche d’âge, sexe, région d’origine, type d’agglomération, niveau d’études, situation professionnelle, revenus financiers, allergies alimentaires, régimes suivis, taille, poids, IMC, nombre de cigarettes fumées, etc.
Les données présentes dans cette table permettent de dresser un aperçu de l’échantillon interrogé dans le cadre de l’étude INCA3. Voici par exemple la répartition de l’échantillon en fonction du genre et de la tranche d’âge :
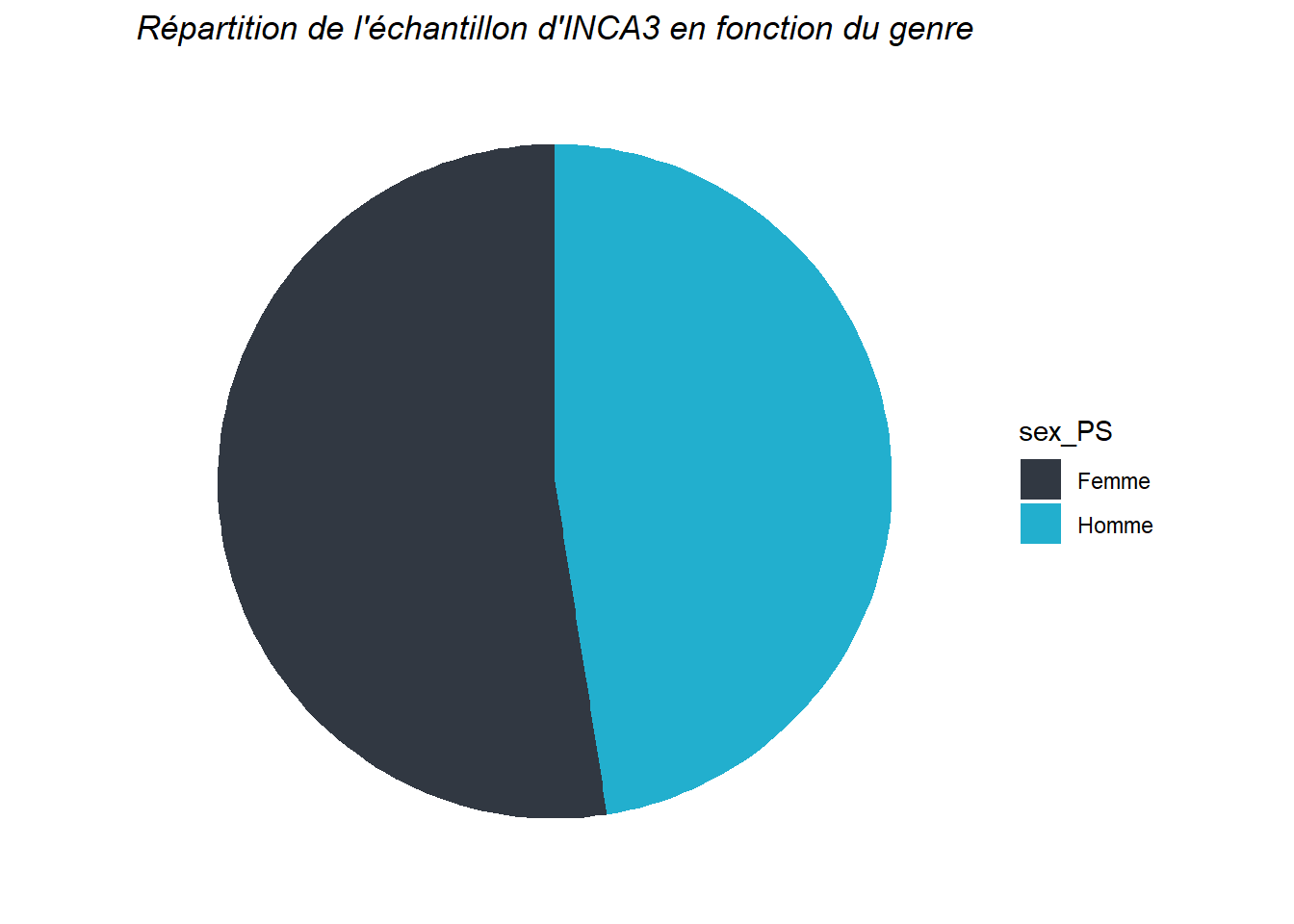
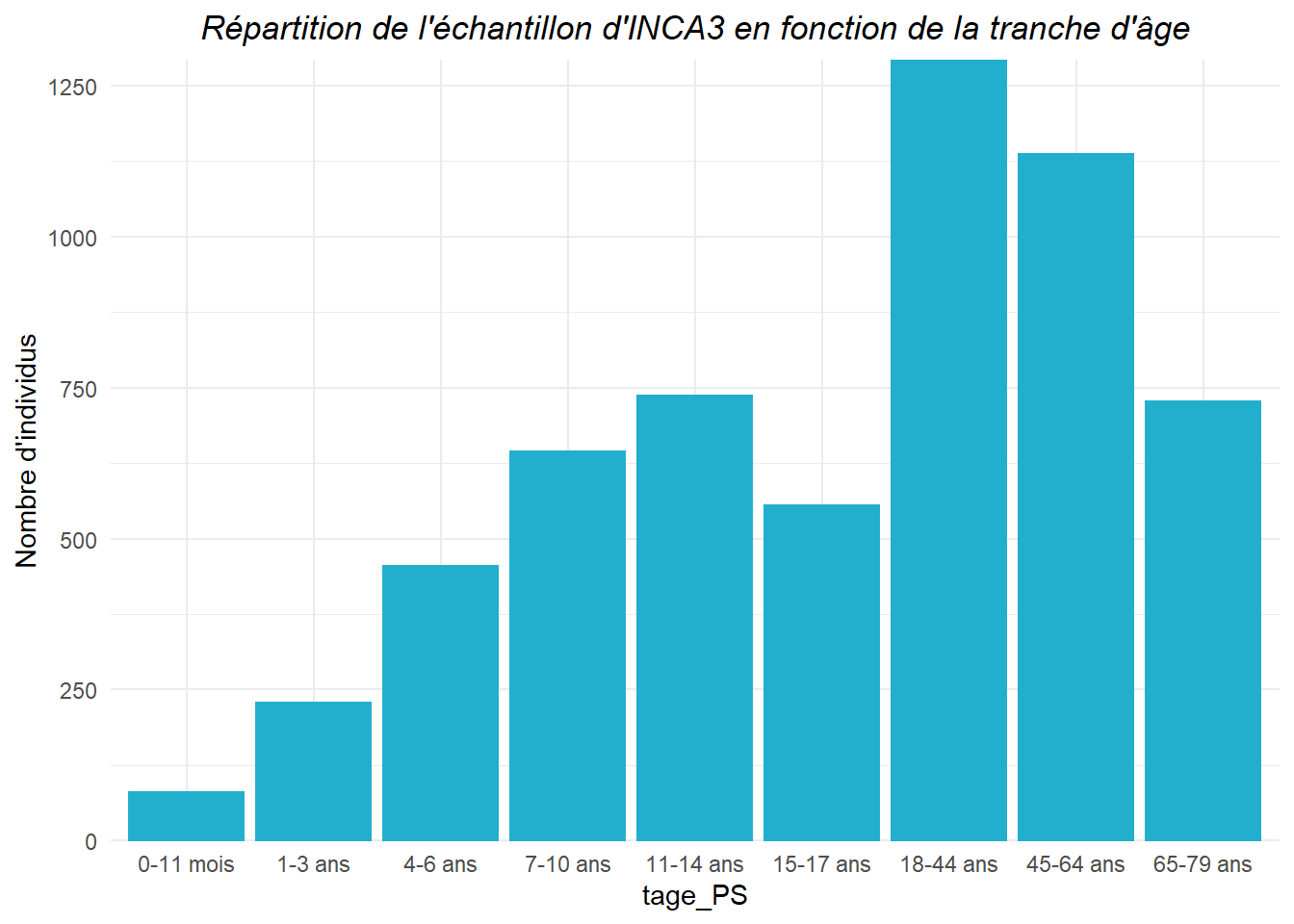
Mais ces données descriptives sur les individus peuvent aussi être utilisées pour répondre à des questionnements plus larges sur la nutrition tels que :
- Quelle proportion des français s’est lancée dans un régime pour perdre du poids ces deux dernières années ?
Ou bien pour répondre à des questions sociétales :
- A partir de quelle tranche de revenus mensuels les français considèrent-ils qu’ils sont à l’aise financièrement ? Inversement, en dessous de quelle tranche de revenus mensuels les français considèrent-ils que leur situation financièrement est très difficile ?
- Quelles catégories socio-professionnelles renoncent le plus à des soins de santé pour des raisons financières ?
Tables relatives aux consommations alimentaires
Table conso_compo_alim_decode
La table conso_compo_alim_decode est l’un des piliers centraux de l’étude INCA3. C’est en effet celle qui contient toutes les données relatives aux consommations alimentaires détaillées et quantifiées des individus interrogés. Pendant 3 jours et pour chaque aliment consommé, les personnes devait notamment indiquer : l’heure de début de la consommation, le type d’occasion (petit-déjeuner, dîner, goûter, apéritif, dans la soirée/nuit, etc.), le lieu de la consommation (à la maison, dans les transports, à la cantine, etc.), l’aliment consommé ainsi que la quantité ingérée (une version pondérée de cette quantité permet de prendre en compte les différences semaine/week-end). Ces données ont par la suite été enrichies grâce à d’autres informations, comme le groupe de l’aliment tel que défini par l’ANSES (yaourts, eau du robinet, matières grasses végétales, etc.) ou les apports en nutriments associés à l’aliment (protéines, glucides, sucres, fibres, sodium, vitamines, etc.).
Voici un petit aperçu de cette table qui affiche les premières données renseignées par l’individu 110100101 lors de sa première journée d’enregistrement (NB : certaines variables ne sont pas affichées) :
D’autres informations sont disponibles dans cette table, notamment le mode de cuisson utilisé pour préparer l’aliment ou le fait que l’aliment soit issu de l’agriculture biologique ou non.
En tant que telle, cette table peut être utilisée pour répondre à des questions du type :
- Quelle est l’assiette type des français sur une journée entière, ou bien par type de moment de consommation ?
- A quelle heure les français mangent-ils ?
Lorsqu’elle est croisée avec des données provenant d’autres tables, il est possible d’étudier l’impact de plusieurs facteurs sur ces phénomènes. Il est par exemple possible de voir comment varie l’assiette type entre un homme et une femme, ou bien entre une personne du Nord de la France par rapport à une personne du Sud, ou bien entre une personne sédentaire et une personne très active.
Tables conso_gpe_inca3_decode, apports_nut_alim_decode et occasions_decode
Ces trois tables sont construites sur la base de la table précédente.
La table conso_gpe_inca3_decode contient les consommations journalières estimées pour chaque catégorie d’aliments (yaourts, eau du robinet, matières grasses végétales, etc.) pour chaque personne. Au total, 44 groupes d’aliments sont indiqués.
La table apports_nut_alim_decode contient, elle, les apports nutritionnels individuels journaliers estimés pour chaque personne.
La table occasions_decode centralise les informations sur les occasions de consommation présentes dans la table conso_compo_alim_decode : jour de consommation, type de jour de consommation (semaine/week-end), type d’occasion de consommation (avant le petit-déjeuner, déjeuner, etc. – tous les types d’occasions sont indiqués), prise ou non d’une consommation, et si oui : heure de la consommation et lieu de la consommation. Cette table permet d’identifier rapidement les individus qui sautent le petit-déjeuner par exemple.
Tables relatives aux compléments alimentaires
Les tables conso_ca_indiv_decode et conso_ca_prod_decode contiennent des informations sur la consommation de Compléments Alimentaires (CA) par les personnes interrogées. Il est notamment possible de savoir quels sont les types de CA consommés (mélanges, plantes ou produits naturels, vitamines et minéraux, etc.), les formes de consommation plébiscitées (sirops, comprimés, etc.), le nombre de jours de consommation par an, mais aussi les raisons qui ont poussé les personnes à consommer des CA.
Tables relatives aux habitudes des individus ou des ménages
Table habitudes_indiv_decode
La table habitudes_indiv_decode fournit des informations sur les habitudes alimentaires des individus interrogés ainsi que sur l’origine des aliments qu’ils consomment. Il est par exemple indiqué dans cette table si la personne amène du sel, du beurre ou de la sauce sur la table au moment des repas. Les personnes interrogées ont également indiqué si elles lisaient les étiquettes pendant leurs achats d’aliments, si elles consommaient des denrées animales crues, ou si elles avaient pour habitude d’acheter des aliments issus de l’agriculture biologique. Pour les enfants de moins de 3 ans, cette table indique quel est leur mode d’alimentation, si la diversification alimentaire a débuté, comment sont préparés les biberons, etc.
Les données de cette table peuvent être utilisées pour mieux connaître les pratiques alimentaires de la population française :
- Quelle proportion des français ont un potager et consomment leurs produits ? Qui sont-ils ? Où vivent-ils ?
- Comment les parents préparent-ils les biberons de leurs enfants en bas-âge ? Respectent-ils les préconisations sanitaires ?
- Quelle proportion des français consomment des aliments issus de l’agriculture biologique ? Qui sont ces consommateurs ?
Table habitudes_men_decode
Contrairement à la table précédente, la table habitudes_men_decode décrit les pratique alimentaires à l’échelle du ménage et non à l’échelle de chaque individu. Elle contient des renseignements sur la préparation et la conservation des aliments au sein du foyer ainsi que sur le traitement de l’eau. Les informations contenues dans cette table permettent d’apporter des réponses aux questions suivantes :
- Est-ce que l’habitude du foyer est de laver et éplucher les fruits et légumes avant leur consommation ? Pour quels fruits ou légumes est-ce le cas ?
- Avec quels types d’ustensiles sont cuits les aliments au sein du foyer ? Des ustensiles en inox, en aluminium, en métal, en céramique ou en fonte ?
- Où sont généralement achetés les fruits et légumes ? La viande ?
- A quelle température est le frigo ?
- Comment sont refroidis les féculents après cuisson ? A température ambiante ? Et, si oui, pendant combien de temps ?
Une partie de ces problématiques permet d’étudier si les français respectent les préconisations sanitaires permettant de limiter les risques microbiologiques inhérents à la préparation des aliments. Par exemple, des féculents cuits ne doivent pas refroidir à température ambiante au risque de voir des bactéries se développer. De la même manière, une certaine température doit être observée dans le frigo pour limiter tout risque microbiologique.
Table fpq_decode
La table fpq_decode rassemble une soixantaine d’aliments ou groupes d’aliments. Pour chacun d’entre eux, la personne interrogée devait indiquer si elle consommait cet aliment, et si oui, à quelle fréquence. Grâce à ces données, il est ainsi possible de déterminer si certains aliments sont sous-consommés au sein de la population française.
Table actphys_sedent_decode
La table actphys_sedent_decode permet de déterminer le niveau d’activité physique et de sédentarité de la personne interrogée. Elle renseigne le niveau d’activité physique de chaque personne (faible, modéré ou élevé), son niveau de sédentarité (faible, modéré ou élevé), et son profil d’activité (comportement inactif et sédentaire, inactif et non sédentaire, actif et sédentaire ou actif et non sédentaire). Un certain nombre de mesures détaillées sont indiquées pour chaque personne : les modes de transport les plus utilisés, la durée moyenne quotidienne passée devant divers types d’écrans (TV, ordinateur, jeux vidéos), le nombre de jours par semaine avec fréquentation d’un club de sport, le nombre de jours travaillés par semaine, le nombre de jours avec activité éducation physique et sportive s’il s’agit d’un enfant, etc. Cette table contient également différents scores qui permettent de mesurer diverses activités physiques (activités sportives et de loisirs, mais également les activités ménagères).
Cette table utilisée seule permet de répondre à des questionnements variés tels que :
- Quel est le niveau global d’activité physique et de sédentarité de la population française ?
- Quels sont les modes de transports privilégiés par les français ?
- Quels sont les sports et loisirs les plus plébiscités à l’échelle nationale ?
Combinée avec d’autres tables telles que description_indiv_decode, ces questionnements peuvent être approfondis :
- Quel est le niveau d’activité physique des enfants selon l’âge et le sexe ?
- Quel est le niveau de sédentarité des adultes selon les caractéristiques socio-démographique ?
- Existe-t-il des différences de pratique sportive entre les hommes et les femmes ?
Petit échantillon d’analyses réalisées grâce au package {inca3}
La fin du combat entre “Pain au chocolat” et “Chocolatine” ?
library(tidyverse)
library(inca3)
library(png)
library(grid)
# Création d'un jeu de données qui contient la quantité de pains au chocolat consommée pendant la durée totale de l'étude INCA3 par région
conso_tot_pain_choc <- left_join(conso_compo_alim_decode %>%
filter(aliment_libelle_INCA3 == "pain au chocolat"),
description_indiv_decode,
by = "NOIND") %>%
group_by(region_inca3) %>%
summarise('qte_total_conso_pain_choc' = sum(qte_conso_pond, na.rm = TRUE)) %>%
arrange(desc(qte_total_conso_pain_choc))
# Création du graphique
ggplot(conso_tot_pain_choc) +
aes(x = reorder(region_inca3, -qte_total_conso_pain_choc), y = qte_total_conso_pain_choc) +
annotation_custom(rasterGrob(pain_choc_background,
width = unit(1, "npc"),
height = unit(1, "npc")),
-Inf, Inf, -Inf, Inf) +
geom_col(color = rgb(34, 175, 206, max = 255), size = 1, fill = rgb(34, 175, 206, max = 255), alpha = 0.4) +
labs(x = "Région",
y = "Quantité de pains au chocolat consommée\n(sur la durée de l'enquête)",
title = "Consommation de pains au chocolat par région") +
theme(axis.text.x = element_text(angle = 45, hjust = 1),
plot.title = element_text(face = "italic", hjust = 0.5),
axis.title = element_text(face = "italic")
) +
scale_y_continuous(labels = function(x) paste(x / 1000, "kg"))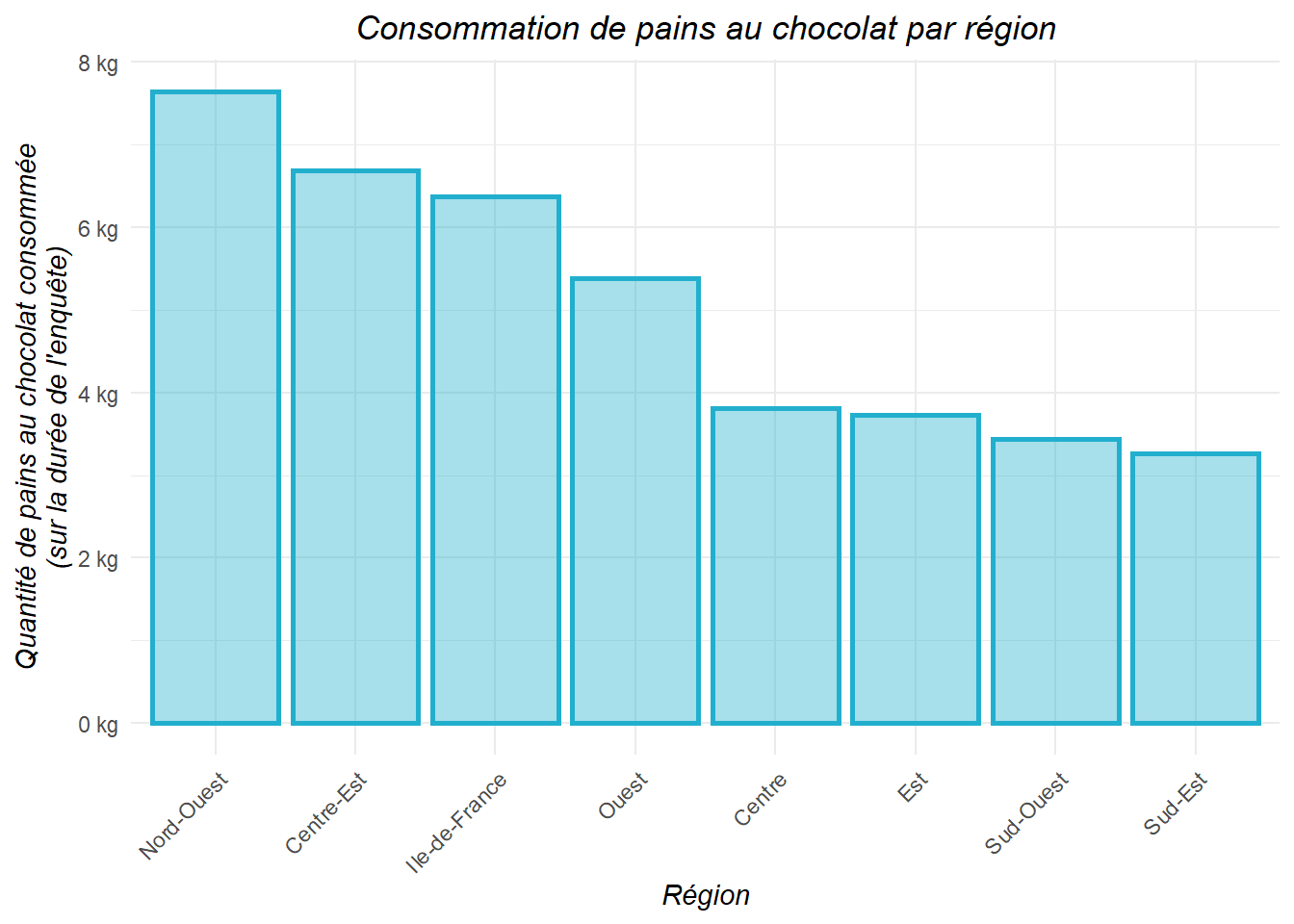
Ce graphique indique que les pains au chocolat sont plus consommés dans les régions dans lesquelles on les appelle… PAINS AU CHOCOLAT !
La boisson alcoolisée plébiscitée par les femmes actives pour l’apéritif est-elle différente de celle plébiscitée par les femmes inactives ?
library(inca3)
library(tidyverse)
library(tidytext)
# Création d'un jeu de données avec la quantité consommée par les femmes au moment de l'apéritif pour chaque boissons alcoolisée et en fonction du profil d'activité/sédentarité de la personne / Top 10 des boissons pour chaque profil d'activité/sédentarité
conso_alcool_apero_femmes <- left_join(left_join(conso_compo_alim_decode,
description_indiv_decode,
by = "NOIND"),
actphys_sedent_decode,
by = "NOIND") %>%
filter(occ_type == "Apéritif avant dîner" & gpe_INCA3 == "Boissons alcoolisées") %>%
filter(sex_PS == "Femme") %>%
group_by(profil_activite, aliment_libelle_INCA3) %>%
summarise(qte_conso_alcool = sum(qte_conso_pond, na.rm = TRUE)) %>%
arrange(profil_activite, desc(qte_conso_alcool)) %>%
filter(!is.na(profil_activite)) %>%
slice(1 : 10) %>%
ungroup
# Création du graphique
ggplot(conso_alcool_apero_femmes) +
aes(x = reorder_within(aliment_libelle_INCA3, qte_conso_alcool, profil_activite), y = qte_conso_alcool) +
geom_col(fill = rgb(237, 77, 40, max = 255)) +
facet_wrap(. ~ profil_activite, ncol = 1, scales = "free") +
scale_x_reordered() +
coord_flip() +
labs(x = "Profil d'activité",
y = "Quantité consommées\n(déclarée sur la durée de l'enquête)",
title = "Top 10 des boissons alcoolisées pour l'apéritif\nplébiscitées par les femmes en fonction de leur profil d'activité") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
plot.title = element_text(face = "italic", hjust = 0.5),
axis.title = element_text(face = "italic")
)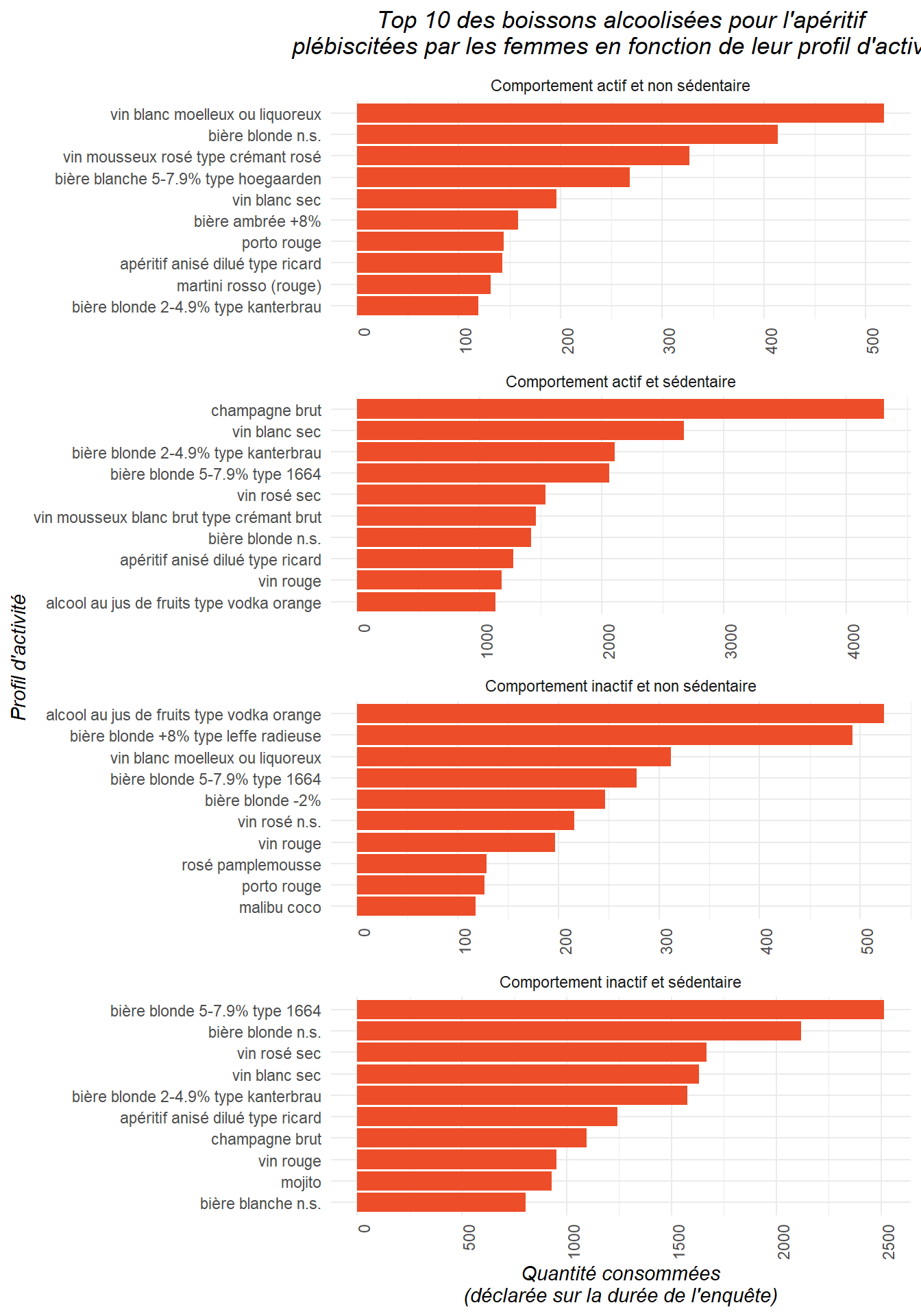
Ce graphique semble montrer que les femmes actives semblent plébisciter le petit verre de vin ou de champagne pour l’apéritif (coucou Bree Van de Kamp !), tandis que les femmes inactives préfèrent une bonne bière…
📢 Enfin, nous ne saurions terminer cet article sans une petite remarque (et pas de la moindre importance !) :
Un camembert 🧀 s’est caché sur cette page, l’avez-vous remarqué ? Aïe aïe aïe !
Mais c’était dans le thème food-friendly, alors on a craqué. Oups.
Pour le pourquoi du comment ce n’est pas une bonne idée, c’est par ici que ça se passe !



Laisser un commentaire