
Vous utilisez Excel pour faire vos graphiques et peut-être même vos analyses statistiques mais vous commencez à avoir marre des difficultés et vous envisagez de passer à R mais vous hésitez, voici des arguments pour arrêter de tergiverser et de sauter le pas 😀
Dans notre dernier article nous avons commencé à comparer Excel et R, nous allons aujourd’hui continuer sur notre lancée en parlant des analyses statistiques de base : test de Student, test du \(\chi\)2 (prononcé Chi ou Khi 2)… et des représentations graphiques : courbe, histogramme…
Sommaire
Les données
Les données utilisées sont les mêmes que dans le dernier article et disponible ici.
Exploration visuelle des données par des graphiques
En fonction du nom du parc
Pour faire une exploration visuelle, nous allons commencer par regarder les données en fonction du nom du parc.
Pour Excel, pas de soucis pour faire un graph de l’année d’ouverture en fonction du nom. Il suffit de sélectionner les colonnes puis Insertion et là vous choisissez le type de graphique, ici nous avons un graphique en courbes auquel la ligne reliant tous les points a été retirée.
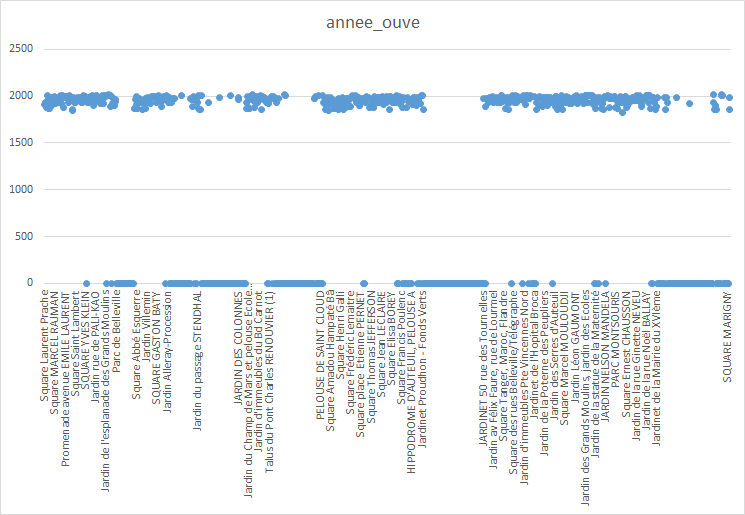
Pour R non plus ce n’est pas difficile, même si l’écriture en ggplot2 peut faire peur aux débutants. Pour plus d’infos à propos de cette syntaxe rendez-vous ici et ici pour un aide mémoire de ggplot2 en français.
library(stringr)
library(ggplot2)
ggplot(donnees_parcs_jardins) + geom_point(aes(x=nom_ev, y=annee_ouve)) + scale_x_discrete(labels = substring(donnees_parcs_jardins$nom_ev,1,20)) + theme(axis.text.x = element_text(size = 5, angle=90))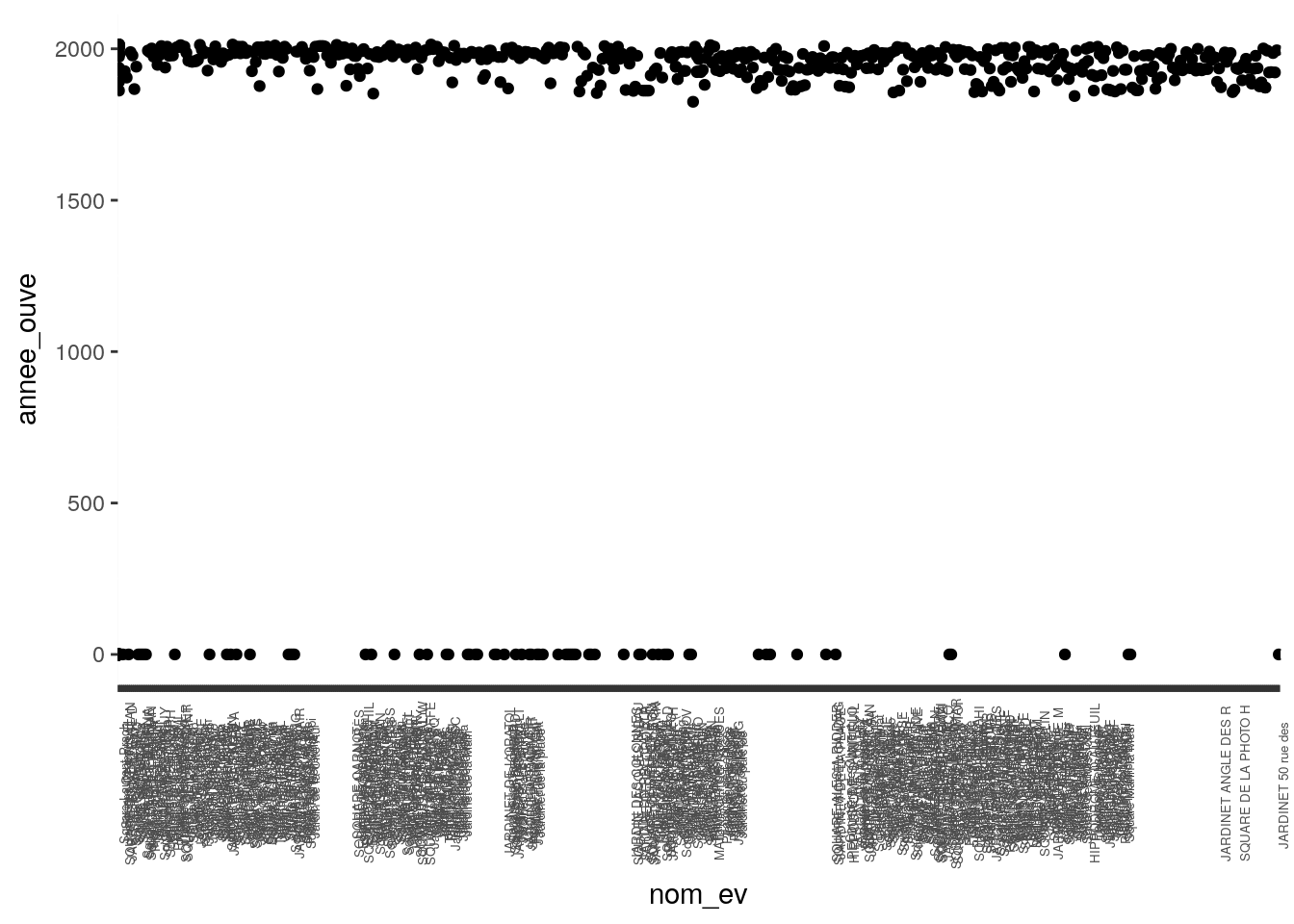
Bon c’est bien beau mais si maintenant je veux le faire pour l’année d’ouverture, l’année de rénovation, l’année ou le nom à changé etc… Comment je fais ?
Et bien avec Excel c’est très simple, il faut tous les faire un par un 😀 !
Avec R il est possible d’automatiser ceci avec deux solutions :
– Faire avec map
– Ecrire une fonction
Les deux solutions sont valables, cela dépend des besoins. La fonction va permettre de rappeler le même format de graphique à nouveau plus tard, le mapping est moins long à écrire.
Il est bien sûre possible de conjuguer les deux 😀 .
library(purrr)
format_de_graphique<-function(df, x, y){
ggplot(df) + geom_point(aes(x = x, y = y)) + scale_x_discrete(labels = substring(x,1,20)) + theme(axis.text.x = element_text(size = 5, angle=90))
}
map(.x = donnees_parcs_jardins[,c(3:5)], .f = ~ format_de_graphique(df = donnees_parcs_jardins, x = donnees_parcs_jardins$nom_ev, y = .x))## $annee_ouve
$annee_reno

$annee_chan

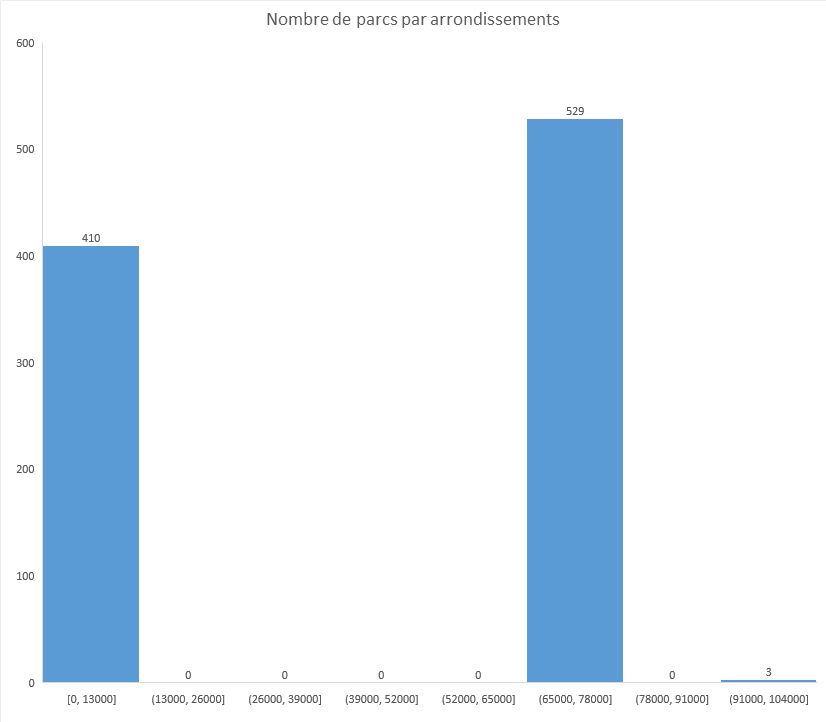
Nombre de parcs par arrondissement
Maintenant interéssons nous un peu plus au données, est-il possible d’avoir rapidement et graphiquement le nombre de parcs par arrondissement ?
Pour Excel, j’ai utilisé un histogramme comme graphique. Le soucis c’est que l’on ne voit pas grand chose à part que 410 parcs n’ont pas d’arrondissement de renseigné et que 3 sont “hors-Paris”.
Pour R, on obtient la même chose sauf que l’on peut “zoomer” en fonction des limites que l’on donne à l’axe des abscisses.
ggplot(donnees_parcs_jardins) + geom_histogram(aes(ardt)) + xlim(75000,75020) + theme_minimal()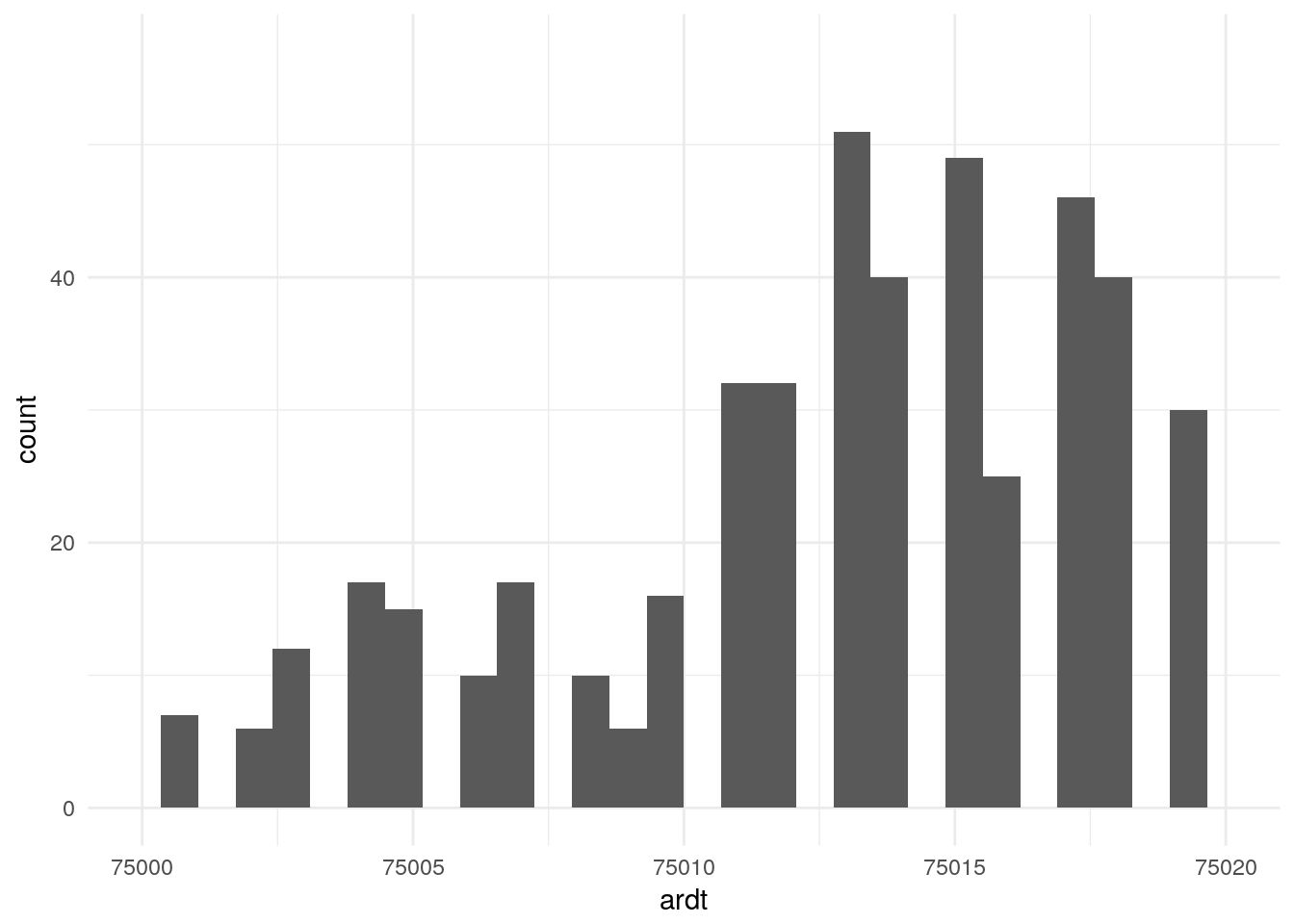
Nombre de parcs ouverts ou fermés
Maintenant regardons le même genre de graphique, la quantité de parcs ouverts et/ou fermés.
Et là, nous avons perdu Excel, impossible pour lui de faire un graphique simple avec une unique variable qualitative alors que cela ne pose pas de soucis à R !
ggplot(donnees_parcs_jardins) + geom_bar(aes(ouvert_fer)) + theme_minimal()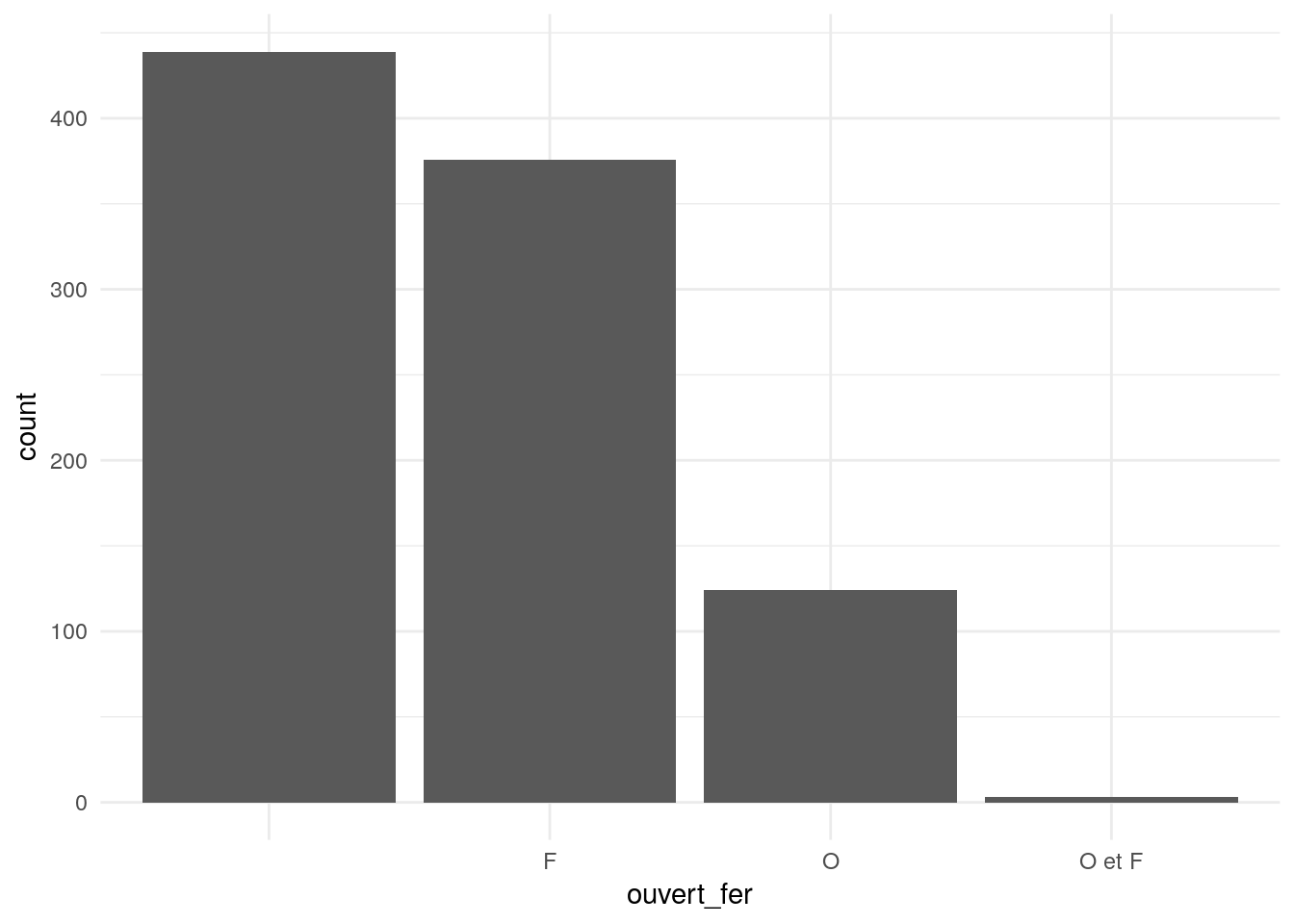
Personnalisation des graphiques
Jusqu’à présent nous nous sommes intéressé aux graphiques basiques mais grâce aux compétences de R nous pouvons faire des graphiques bien plus poussées mais nous ne les détaillerons pas ici.
Maintenant on va regarder un peu les statistiques que l’on peut faire sur les données.
Analyse statistique
Statistiques univariées
Les statistiques univariées ont pour but de décrire une variable.
Variables qualitatives
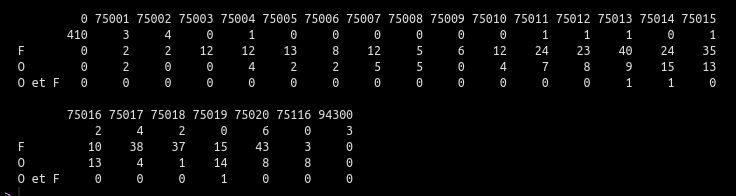
Pour les variables qualitatives on peut regarder la nombre qu’il y a dans chaque catégorie.
Si R le fait très facilement avec par exemple la fonction table du package de base pour Excel encore une fois, c’est plus compliqué.
Il faut utiliser la fonction NB.SI(Plage = donnes_a_lire, Critère) et faire chaque catégorie une par une. Par exemple pour connaître le nombre de parcs “ouverts”, “fermés”, non-renseigné et “ouverts et fermé”, il faut marquer les formules suivantes dans 4 cellules différentes :
– NB.SI(Plage = I:I, "O") – NB.SI(Plage = I:I, "F") – NB.SI(Plage = I:I, "") – NB.SI(Plage = I:I, "O et F")
Quatre c’est encore faisable, pour faire tous les arrondissements c’est l’horreur et si vous voulez croiser les deux je vous laisse imaginer le travail (avec la fonction NB.SI.ENS() si vous voulez vous amuser…).
Variables quantitatives
Là ça va mieux pour Excel, trouver le minimum (MIN()) ou le maximum (MAX()) calculer une moyenne (MOYENNE()), la variance(VAR()), l’écart-type (ECARTYPE.PEARSON()), une médiane (MEDIANE()), des quartiles (QUARTILES()), il sait faire.
Il faut le faire un paramètre à la fois, mais ça va.
Bon évidement R le fais mieux 🙂 avec min(), max(), mean(), var, sd(), median(), quantile() du package {base}.
Statistiques bivariées
Corrélation
Excel a une fonction qui permet de donner la covariance entre deux variables COEFFICIENT.CORRELATION() mais elle ne donne ni le degré de liberté ni la statistique de test associé.
Avec R il existe deux fonction du package {stats}, cor() qui donne la même chose que la fonction Excel et cor.test() qui donne plus d’informations.
L’avantage de R par rapport à Excel, c’est que l’on peut modifier le niveau de confiance, la méthode utilisée…
cor(donnees_parcs_jardins$annee_ouve, donnees_parcs_jardins$annee_reno)## [1] 0.2007289cor.test(donnees_parcs_jardins$annee_ouve, donnees_parcs_jardins$annee_reno)
## Pearson's product-moment correlation
## data: donnees_parcs_jardins$annee_ouve and donnees_parcs_jardins$annee_reno
## t = 6.2821, df = 940, p-value = 5.101e-10
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.1386325 0.2612532
## sample estimates:
## 0.2007289
Les autres tests
Comme précédemment, Excel et R peut faire des tests statistiques simples : test de Student (T.TEST() et t.test()), test du Chi 2 (CHISQ.TEST() et chisq.test()), comparaison de deux variances (F.TEST() et var.test).
A chaque fois Excel donne la valeur simple sans autre information quand R est plus généreux.
Statistiques multivariés
En téléchargeant l’utilitaire d’analyse Analysis ToolPak dans Excel il est possible de faire quelques tests multivariés comme des ANOVA mais c’est moins puissant qu’Excel.
Par exemple, l’ANOVA est limité à une facteur explicatif qualitatif et un quantitatif.
A vous de voir en fonction de vos besoin 😀 .
Vous avez encore des doutes sur le fait d’abandonner Excel pour R, allez voir le tweet d’Ettore Rizza.
Voici pour le deuxième et dernier article de comparaison d’Excel et de R dans Rstudio. En espérant que ça vous ai encore plus donné envie de pratiquer R 😉 .
Si vous avez des questions n’hésitez pas à nous en faire part dans les commentaires.




Laisser un commentaire