
{dplyr} est un package du tidyverse (ancien hadleyverse, et que l’on connait sous le nom d’ordocosme) dédié à faciliter la manipulation, l’exploration et les calculs sur des données. Devenu incontournable en peu de temps, il a l’avantage de présenter un environnement unifié de fonctions dédiées : la grammaire de la manipulation des données (toute ressemblance avec une grammaire des graphiques du même auteur serait purement fortuite…).
Sommaire
Importer un jeu de données d’exemple
Pour vous faire la démonstration de ses potentialités, nous utiliserons un jeu de données issu de la Ville de Paris et ses espaces verts : leur nom, leur localisation géographique, leur année d’ouverture, leur statut (fermé, ouvert), leur surface, l’adresse et l’arrondissement…
L’import est réalisé via la fonction read_csv2 de {readr} (encore un package d’Hadley Wickham)
library(readr)
library(dplyr)
jardins <- read_csv2("http://opendata.paris.fr/explore/dataset/parcsetjardinsparis2010/download/?format=csv&timezone=Europe/Berlin&use_labels_for_header=true")
class(jardins)
## [1] "tbl_df" "tbl" "data.frame"Le package dplyr utilise un format de données qui n’est pas le data.frame mais tbl_df. Ce format est différent de l’affichage classique dans la mesure où :
- la structure de la variable est donnée entre parenthèses sous chaque nom de variable (“Moui…”)
- des informations concernant le jeu de données, notamment ses dimensions (
Source: local data frame), sont affichées dans la partie supérieure de l’affichage (“Ah…”) - seules les variables qui peuvent être entièrement affichées dans la fenêtre sont visibles (“ Sympa !“)
- ET seules les premières lignes sont affichées. Exit l’attente interminable due à l’affichage dans la console des 5000 premières lignes d’un data.frame (“TROP GENIAAAAAL…”)
C’est donc un head(), dim() et str() adapté à la taille de la fenêtre pour le prix d’un as.tbl_df() sur un data.frame
Démonstration sur le jeu de données, privé de ses 2 premières colonnes (particulièrement riches en informations…) avec les outils de base de sélection :
jardins[,-c(1:2)]
## Source: local data frame [942 x 10]
##
## ANNEE OUVERTURE ANNEE RENOVATION ANNEE CHANGEMENT
## (int) (int) (int)
## 1 1909 0 1934
## 2 1933 0 1933
## 3 1928 0 1999
## 4 1884 0 0
## 5 2004 2009 2013
## 6 1870 0 1912
## 7 1967 0 0
## 8 1865 0 1955
## 9 1891 0 0
## 10 1987 0 0
## .. ... ... ...
## Variables not shown: NOM_EV (chr), ANCIEN NOM (chr), NUMERO (int), STATUT
## (chr), SURFACE ADMINISTRATIVE (m²) (chr), ADRESSE (chr), ARRONDISSEMENT
## (int)
La fonction read_csv2 n’intègre pas de make.names() avec les noms de variables comme read.csv2. Par ailleurs, elle laisserait deux noms de variables identiques si tel était le cas dans le jeu de données d’origine, il est de bon ton de compléter l’ import avec :
names(jardins)
## [1] "Geo point" "Geo Shape"
## [3] "ANNEE OUVERTURE" "ANNEE RENOVATION"
## [5] "ANNEE CHANGEMENT" "NOM_EV"
## [7] "ANCIEN NOM" "NUMERO"
## [9] "STATUT" "SURFACE ADMINISTRATIVE (m²)"
## [11] "ADRESSE" "ARRONDISSEMENT"
names(jardins) <- make.names(names(jardins))
names(jardins) <- make.unique(names(jardins))
names(jardins)
## [1] "Geo.point" "Geo.Shape"
## [3] "ANNEE.OUVERTURE" "ANNEE.RENOVATION"
## [5] "ANNEE.CHANGEMENT" "NOM_EV"
## [7] "ANCIEN.NOM" "NUMERO"
## [9] "STATUT" "SURFACE.ADMINISTRATIVE..m²."
## [11] "ADRESSE" "ARRONDISSEMENT"
Bon, assez vanté les mérites de {dplyr}, allons maintenant cruncher de la data !
Les principaux verbes de manipulation des données
Nous vous présenteront ici 5 des principaux verbes du package {dplyr}. Il en existe d’autres, mais les verbes ci-dessous sont particulièrement indispensables.
Ils ont tous en commun de prendre comme premier argument le nom du jeu de données sur lequel opérer les manipulations. Moui, cette précision peut sembler peu intéressante là, tout de suite maintenant… patience, ce sera important un peu plus bas.
select()
select() est un verbe, qui comme son nom l’indique, permet de sélectionner des variables :
select(jardins, NOM_EV)
## Source: local data frame [942 x 1]
##
## NOM_EV
## (chr)
## 1 Square Laurent Prache
## 2 Square Ozanam
## 3 Jardin des Champs Elysées, Jardin de la Vallée Suisse
## 4 SQUARE DU VERT GALANT
## 5 JARDINET MADELEINE DE SCUDERY
## 6 Square Boucicaut
## 7 Square Pierre de GAULLE
## 8 Square Santiago du Chili
## 9 Square des Recollets et quai du canal rive droite
## 10 Jardin de l'église St-Jean-Denys Bühler
## .. ...Le premier argument est le nom du jeu de données, le second (et les suivants) sont les noms des variables à sélectionner. Contrairement à la sélection classique, nul besoin de mettre des " ".
jardins[,c("NOM_EV","ANCIEN.NOM")]
# est équivalent à :
select(jardins, NOM_EV,ANCIEN.NOM)Pour l’instant, peu d’intérêt par rapport à la fonction [ ] de {base}
Sauf que…
Il est possible de sélectionner plusieurs colonnes contiguës avec “:”
select(jardins, ANCIEN.NOM:NUMERO)Il est aussi possible d’anti-sélectionner par les noms de variables :
select(jardins, -Geo.point, -Geo.Shape)Par ailleurs d’autres fonctions utiles de sélection sont pré-implémentées :
select(jardins, -starts_with("Geo"))
select(jardins, starts_with("annee", ignore.case=TRUE))
select(jardins, ends_with("MENT"))
select(jardins, -contains("²"))Enfin, si elles manquent de flexibilité, il est toujours possible d’utiliser les expressions régulières (ou regex) dans la fonction matches :
select(jardins, matches("._."))Là, ça devient plus intéressant.

filter()
Le deuxième verbe central de dplyr est filter. Il permet de filtrer les lignes du jeu de données qui satisfont un critère. Son écriture est très proche de la fonction subset :
filter(jardins, ANNEE.OUVERTURE > 2000)
## Source: local data frame [69 x 12]
##
## Geo.point
## (chr)
## 1 48.8629932656, 2.36178244042
## 2 48.8755344696, 2.36956498547
## 3 48.8558915275, 2.38556628083
## 4 48.8278897411, 2.36622789227
## 5 48.8918337594, 2.30457435953
## 6 48.8390737304, 2.33112462915
## 7 48.8953076257, 2.3199139058
## 8 48.8292834984, 2.38018046046
## 9 48.8289663796, 2.37924610195
## 10 48.8287395627, 2.36787243239
## .. ...
## Variables not shown: Geo.Shape (chr), ANNEE.OUVERTURE (int),
## ANNEE.RENOVATION (int), ANNEE.CHANGEMENT (int), NOM_EV (chr), ANCIEN.NOM
## (chr), NUMERO (int), STATUT (chr), SURFACE.ADMINISTRATIVE..m². (chr),
## ADRESSE (chr), ARRONDISSEMENT (int)Avec plusieurs critères :
# ces 2 écritures sont identiques :
filter(jardins, ANNEE.RENOVATION == 0 & ANNEE.CHANGEMENT == 0)
filter(jardins, ANNEE.RENOVATION == 0 , ANNEE.CHANGEMENT == 0)
# le symbole | (ou) s'utilise comme en base :
filter(jardins, ANNEE.RENOVATION == 0 | ANNEE.CHANGEMENT == 0)
filter(jardins, ANNEE.OUVERTURE > 2000 | ARRONDISSEMENT == 75010)
C’est pas mal, mais pas transcendantal encore…
arrange()
Une autre opération utile consiste à trier le jeu de données, dans l’ordre croissant ou décroissant selon un ou plusieurs critères : c’est le job d’arrange()
Par défaut, le tri se fait en ordre croissant :
arrange(jardins, ARRONDISSEMENT)
## Source: local data frame [942 x 12]
##
## Geo.point
## (chr)
## 1 48.8587620076, 2.3222813399
## 2 48.8459563976, 2.3443304597
## 3 48.8432345727, 2.34680090241
## 4 48.852749767, 2.34711275746
## 5 48.8436879364, 2.31199221212
## 6 48.8493747659, 2.35069374
## 7 48.8508695053, 2.35101031137
## 8 48.8491469168, 2.34595249386
## 9 48.8358856183, 2.33047558575
## 10 48.850605773, 2.30645296437
## .. ...
## Variables not shown: Geo.Shape (chr), ANNEE.OUVERTURE (int),
## ANNEE.RENOVATION (int), ANNEE.CHANGEMENT (int), NOM_EV (chr), ANCIEN.NOM
## (chr), NUMERO (int), STATUT (chr), SURFACE.ADMINISTRATIVE..m². (chr),
## ADRESSE (chr), ARRONDISSEMENT (int)C’est en utilisant la fonction desc() que le tri se fait en ordre décroissant. Un genre de decreasing = TRUE de la fonction sort() :
arrange(jardins, desc(ARRONDISSEMENT))
## Source: local data frame [942 x 12]
##
## Geo.point
## (chr)
## 1 48.844984407, 2.4392078324
## 2 48.8412780968, 2.433270059
## 3 48.846129541, 2.43944343804
## 4 48.8726188095, 2.2839767565
## 5 48.8676055587, 2.27318458883
## 6 48.8716221114, 2.27492835199
## 7 48.8755429796, 2.27762407541
## 8 48.869127402, 2.27268688789
## 9 48.8654143321, 2.29669091491
## 10 48.8764801743, 2.28087941617
## .. ...
## Variables not shown: Geo.Shape (chr), ANNEE.OUVERTURE (int),
## ANNEE.RENOVATION (int), ANNEE.CHANGEMENT (int), NOM_EV (chr), ANCIEN.NOM
## (chr), NUMERO (int), STATUT (chr), SURFACE.ADMINISTRATIVE..m². (chr),
## ADRESSE (chr), ARRONDISSEMENT (int)Rien n’empêche de multiplier les critères de tri, il suffit de les séparer par des virgules, comme pour select ou filter :
arrange(jardins, desc(ARRONDISSEMENT), ANNEE.OUVERTURE)
## Source: local data frame [942 x 12]
##
## Geo.point
## (chr)
## 1 48.844984407, 2.4392078324
## 2 48.8412780968, 2.433270059
## 3 48.846129541, 2.43944343804
## 4 48.8726188095, 2.2839767565
## 5 48.8614200435, 2.28941749601
## 6 48.8679710046, 2.29424259116
## 7 48.8654143321, 2.29669091491
## 8 48.8629977301, 2.28712679598
## 9 48.8755429796, 2.27762407541
## 10 48.869127402, 2.27268688789
## .. ...
## Variables not shown: Geo.Shape (chr), ANNEE.OUVERTURE (int),
## ANNEE.RENOVATION (int), ANNEE.CHANGEMENT (int), NOM_EV (chr), ANCIEN.NOM
## (chr), NUMERO (int), STATUT (chr), SURFACE.ADMINISTRATIVE..m². (chr),
## ADRESSE (chr), ARRONDISSEMENT (int)
Et comment sont gérées les données manquantes dans les arrange ? Elles sont reléguées en fin de tableau, peu importe l’ordre dans lequel sont triées les valeurs – croissant ou décroissant.
mutate()
mutate est le verbe qui permet la transformation d’une variable existante ou la création d’une nouvelle variable dans le jeu de données. C’est le verbe à utiliser dès lors qu’on utilise $ et <- dans la même instruction, comme dans :
dataset$nouvelle_variable <- opération sur une ancienne_variable
# ou
dataset$ancienne_variable <- opération sur une ancienne_variableAvec le jeu de données des espaces verts de la ville de Paris, l’utilisation de la fonction read_csv2 conduit à la lecture de la variable SURFACE.ADMINISTRATIVE..m². comme un facteur. C’est donc une occasion rêvée pour utiliser la fonction mutate afin de transformer la variable en numeric :
jardins <- mutate(jardins,
SURFACE.ADMINISTRATIVE..m².= as.numeric(as.character(SURFACE.ADMINISTRATIVE..m².)))
summary(jardins$SURFACE.ADMINISTRATIVE..m².)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0 252.5 1376.0 5411.0 4014.0 247300.0mutate est une fonction dite “window” l’opération qui est réalisée sur la variable restitue une variable de même taille. C’est une transformation :
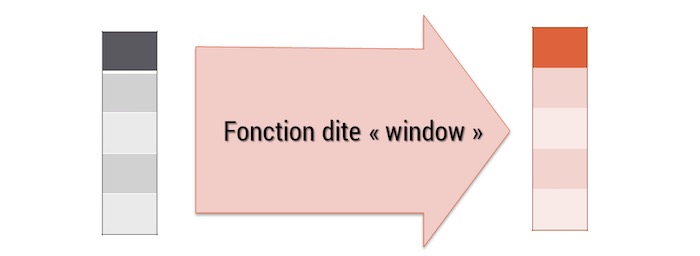
summarise()
summarize (… ou summarise, c’est pareil… il s’agirait de ne pas froisser les susceptibilités) est une fonction dite de “résumé”. À l’inverse de mutate, quand une fonction summarize est appelée, elle retourne une seule information. La moyenne, la variance, l’effectif…sont des informations qui condensent la variable étudiée en une seule information.
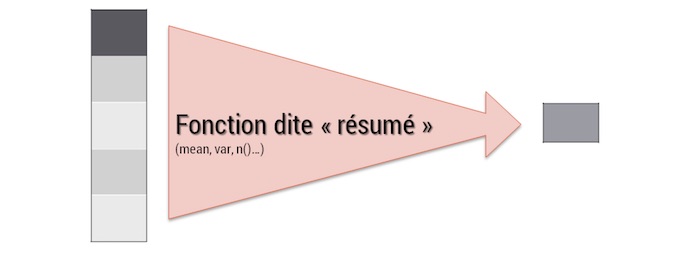
Le résultat d’une fonction summarise est un tbl_df.
summarise(jardins, surface_moyenne=mean(SURFACE.ADMINISTRATIVE..m².))
## Source: local data frame [1 x 1]
##
## surface_moyenne
## (dbl)
## 1 5410.904summarise peut parfaitement calculer plusieurs indicateurs à la fois : il suffit de séparer les calculs d’une virgule :
summarise(jardins,
surface_moyenne = mean(SURFACE.ADMINISTRATIVE..m².),
ecart_type = sd(SURFACE.ADMINISTRATIVE..m².))
## Source: local data frame [1 x 2]
##
## surface_moyenne ecart_type
## (dbl) (dbl)
## 1 5410.904 17105.24Le tbl_df retourné par la fonction summarise a donc autant de colonnes que de variables calculées.
Enchaîner les opérations de manipulation des données

Le package {magrittr} (que l’on prononce naturellement, nous francophones, avec un accent sophistiqué – cf vignette("magrittr") ) propose un opérateur codé %>% dont le rôle est d’éviter l’imbrication des fonctions les unes dans les autres, par exemple :
jardins %>% head()
# est équivalent à :
head(jardins)%>% peut être lu comme « ensuite » ou « puis ». Dans l’exemple précédent, on lirait « Prends le jeu de données jardins ensuite (%>% ) réalise l’instruction qui consiste à renvoyer les 6 premières lignes du jeu de données (head()) »
L’opérateur %>% passe comme premier argument à la fonction qu’on trouve immédiatement à sa droite (ici head()) ce qui se trouve à sa gauche (ici jardins) – il est conseillé de lire cette phrase plusieurs fois en détachant chaque mot pour bien en comprendre le sens.
Le génie de cette fonction %>% n’est pas pleinement exprimé dans cet exemple, puisque qu’on ne gagne pas particulièrement en lisibilité ou en frappe sur le clavier. Son intérêt réside en fait dans le chaînage des opérations de manipulation sur la base de données. C’est pour cette raison que le mariage avec {dplyr} est un mariage consommé :
jardins %>%
filter(ARRONDISSEMENT %in% c(75010, 75011, 75012)) %>%
summarise(surface_totale = sum(SURFACE.ADMINISTRATIVE..m².)) %>%
mutate(
surface_totale_ha = surface_totale / 10000,
surface_totale_km2 = surface_totale_ha / 100
)
## Source: local data frame [1 x 3]
##
## surface_totale surface_totale_ha surface_totale_km2
## (dbl) (dbl) (dbl)
## 1 425442 42.5442 0.425442Cette instruction pourrait se traduire par la phrase suivante : “A partir de jardins, je réalise un filtre sur le 10ème, 11ème et 12ème arrondissement, ensuite je calcule la surface administrative pour ces espaces verts (le résultat est un tbl_df), ensuite, je calcule dans ce nouveau tableau une nouvelle variable surface_totale_ha en hectares et à partir de cette dernière je calcule surface_totale_km2 en km²”
On peut donc, dans une même fonction mutate, construire plusieurs variables et même construire des variables à partir de celles calculées à la volée dans mutate (attention toutefois à l’ordre des instructions). L’enchaînement des instructions de manipulation constitue un “pipe” (définition wiktionnaire) comme si les données étaient passées dans un tuyau. L’indentation du code après chaque %>% rend aisée la lecture mais aussi la possibilité de passer rapidement en commentaires certaines instructions :
jardins %>%
#filter(ARRONDISSEMENT %in% c(75010, 75011, 75012)) %>%
summarise(surface_totale = sum(SURFACE.ADMINISTRATIVE..m².)) %>%
mutate(
surface_totale_ha = surface_totale / 10000,
surface_totale_km2 = round(surface_totale_ha)
)
## Source: local data frame [1 x 3]
##
## surface_totale surface_totale_ha surface_totale_km2
## (dbl) (dbl) (dbl)
## 1 5097071 509.7071 510
“Piper” dans le désordre : “.”
Comme défini plus haut, “L’opérateur %>% passe ce qu’on trouve à sa gauche en premier argument de la fonction qu’on trouve immédiatement à sa droite” : comment faire alors quand je souhaite passer à droite du pipe un argument qui n’est pas en première position dans la fonction que je souhaite utiliser ? C’est le cas de qplot() du package {ggplot2}(cf notre « Guide de survie ggplot2 à destination des datajournalistes (et des autres aussi)« )
library(ggplot2)
jardins %>%
filter(ANNEE.OUVERTURE != 0) %>%
qplot(x = ANNEE.OUVERTURE, data = .,
geom = "histogram",
main = "Ouvertures des parcs de Paris au cours du temps")
Réaliser les traitements par groupe dans un “pipe”
Découper un jeu de données pour réaliser des opérations sur chacun des sous-ensembles afin de les restituer ensuite de façon organisée est appelée stratégie du split – apply – combine schématiquement, c’est cette opération qui est réalisée par la fonction {dplyr}, qui prend en charge la notion de “split” est group_by(). Dans un pipe, dès lors qu’un group_by est introduit, toutes les opérations qui suivent sont réalisées pour chacun des sous-ensembles de la base. 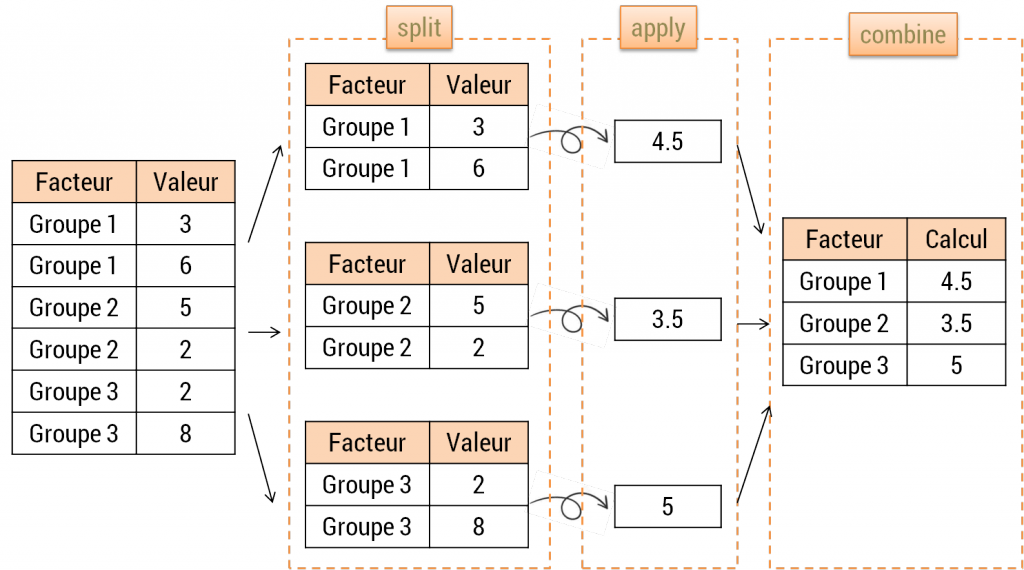 Par exemple :
Par exemple :
jardins %>%
group_by(ARRONDISSEMENT) %>%
mutate(prop_arrondissement = SURFACE.ADMINISTRATIVE..m². / sum(SURFACE.ADMINISTRATIVE..m².)) %>%
select(NOM_EV, SURFACE.ADMINISTRATIVE..m².,prop_arrondissement)
## Source: local data frame [942 x 4]
## Groups: ARRONDISSEMENT [23]
##
## ARRONDISSEMENT NOM_EV
## (int) (chr)
## 1 75006 Square Laurent Prache
## 2 75006 Square Ozanam
## 3 75008 Jardin des Champs Elysées, Jardin de la Vallée Suisse
## 4 75001 SQUARE DU VERT GALANT
## 5 75003 JARDINET MADELEINE DE SCUDERY
## 6 75007 Square Boucicaut
## 7 75007 Square Pierre de GAULLE
## 8 75007 Square Santiago du Chili
## 9 75010 Square des Recollets et quai du canal rive droite
## 10 75007 Jardin de l'église St-Jean-Denys Bühler
## .. ... ...
## Variables not shown: SURFACE.ADMINISTRATIVE..m². (dbl),
## prop_arrondissement (dbl)Les proportions de surfaces totales calculées ici le sont par arrondissement. Via la fonction mutate, c’est une nouvelle variable qui est construite et additionnée au jeu de données. Même si dans la fonction select ce sont 3 variables qui sont sélectionnées, dès lors qu’un group_by() est présent dans le pipe, le résultat restitué en tbl_df avec les variables concernées par le group_by (ici ARRONDISSEMENT).
Comment savoir si un jeu de données est groupé ?
jardins %>%
group_by(ARRONDISSEMENT) %>%
head(1)
## Source: local data frame [1 x 12]
## Groups: ARRONDISSEMENT [1]
##
## Geo.point
## (chr)
## 1 48.8542589475, 2.33394041771
## Variables not shown: Geo.Shape (chr), ANNEE.OUVERTURE (int),
## ANNEE.RENOVATION (int), ANNEE.CHANGEMENT (int), NOM_EV (chr), ANCIEN.NOM
## (chr), NUMERO (int), STATUT (chr), SURFACE.ADMINISTRATIVE..m². (dbl),
## ADRESSE (chr), ARRONDISSEMENT (int)L’information se situe dans l’entête du tbl_df : Groups: ARRONDISSEMENT [1]
Un autre exemple de group_by dans un pipe :
jardins %>%
group_by(ARRONDISSEMENT) %>%
summarise(surface_admin = sum(SURFACE.ADMINISTRATIVE..m².))
## Source: local data frame [23 x 2]
##
## ARRONDISSEMENT surface_admin
## (int) (dbl)
## 1 0 868997.1
## 2 75001 48652.0
## 3 75002 2852.0
## 4 75003 24379.0
## 5 75004 53733.0
## 6 75005 75313.0
## 7 75006 28296.0
## 8 75007 373011.0
## 9 75008 246611.0
## 10 75009 14706.0
## .. ... ...Transformer et résumer l’information en blocs
La table jardins contient des zéros dans les variables numériques en lieu et place des données manquantes. Remplaçons-les par des données manquantes avec une fonction mutate en utilisant une fonction écrite pour l’occasion :
remplacer_les_zeros <- function(vecteur){vecteur[vecteur==0] <- NA ; return(vecteur)}
jardins %>%
mutate(
ANNEE.OUVERTURE = remplacer_les_zeros(ANNEE.OUVERTURE),
ANNEE.RENOVATION = remplacer_les_zeros(ANNEE.RENOVATION),
ANNEE.CHANGEMENT = remplacer_les_zeros(ANNEE.CHANGEMENT),
NUMERO = remplacer_les_zeros(NUMERO),
SURFACE.ADMINISTRATIVE..m². = remplacer_les_zeros(SURFACE.ADMINISTRATIVE..m².),
ARRONDISSEMENT = remplacer_les_zeros(ARRONDISSEMENT)
)
## Source: local data frame [942 x 12]
##
## Geo.point
## (chr)
## 1 48.8542589475, 2.33394041771
## 2 48.8433404323, 2.32743459837
## 3 48.8671092958, 2.314863253
## 4 48.8574030485, 2.3402680069
## 5 48.8629932656, 2.36178244042
## 6 48.8513733092, 2.32576296924
## 7 48.8509757174, 2.31318931954
## 8 48.8574726968, 2.31091880644
## 9 48.8735386295, 2.36360777984
## 10 48.8575204746, 2.30804038492
## .. ...
## Variables not shown: Geo.Shape (chr), ANNEE.OUVERTURE (int),
## ANNEE.RENOVATION (int), ANNEE.CHANGEMENT (int), NOM_EV (chr), ANCIEN.NOM
## (chr), NUMERO (int), STATUT (chr), SURFACE.ADMINISTRATIVE..m². (dbl),
## ADRESSE (chr), ARRONDISSEMENT (int)Plutôt répétitif, non ? Il doit bien y avoir une astuce…On parle d’un package implémenté par la personne qui dit qu’il faut faire une fonction à partir de 2 copier-coller et un package à partir de 2 fonctions.
Une même fonction est utilisée plus de 2 fois sur les variables du jeu de données ? Voila un job pour mutate_each :
jardins <- mutate_each(jardins, funs(remplacer_les_zeros), -Geo.point, -Geo.Shape, -NOM_EV, -ANCIEN.NOM,-STATUT,-ADRESSE)
EDIT : Notez que mutate_each est obsolète, regardez mutate_at ou mieux ici comment utiliser across dans {dplyr} v1.0
La syntaxe de la fonction est un soupçon plus difficile à appréhender ici. mutate_each_(tbl, funs, vars) où tbl est le tbl_df sur lequel on souhaite transformer les variables, funs les fonctions à appliquer et vars les variables sur lesquelles appliquer les funs. On remarquera que les moyens de sélection des vars sont les mêmes que pour la fonction select. C’est pour cette raison qu’il est possible d’anti-selectionner par les noms des variables comme dans l’exemple ci-dessus.
De la même façon, si l’on souhaite, non plus transformer, mais résumer l’information avec une ou plusieurs fonctions sur plusieurs variables, le pendant de mutate_each est summarise_each. Un exemple avec plusieurs funs :
jardins %>%
summarise_each(funs(median,mean), ANNEE.OUVERTURE:ANNEE.CHANGEMENT)
## Source: local data frame [1 x 6]
##
## ANNEE.OUVERTURE_median ANNEE.RENOVATION_median ANNEE.CHANGEMENT_median
## (int) (int) (int)
## 1 NA NA NA
## Variables not shown: ANNEE.OUVERTURE_mean (dbl), ANNEE.RENOVATION_mean
## (dbl), ANNEE.CHANGEMENT_mean (dbl)Le résultat retourné ici est un tbl_df d’une ligne et d’autant de colonnes qu’il y a de variables x nombre de fonctions. Les variables sont retournées dans l’ordre variable1_fonction1,variable2_fonction1,variable3_fonction1…
EDIT : Notez que summarise_each est obsolète, regardez summarise_at ou mieux ici comment utiliser across dans {dplyr} v1.0
Ce tbl_df ne contient que des données manquantes. C’est fâcheux. Mais c’est aussi une excellente occasion de passer des arguments aux fonctions mean et median ! Et l’on retrouve . pour passer les arguments nécessaires à l’exécution des fonctions :
jardins %>%
summarise_each(funs(median(.,na.rm=TRUE),mean(.,na.rm=TRUE)),
ANNEE.OUVERTURE:ANNEE.CHANGEMENT)
## Source: local data frame [1 x 6]
##
## ANNEE.OUVERTURE_median ANNEE.RENOVATION_median ANNEE.CHANGEMENT_median
## (int) (int) (dbl)
## 1 1974 2003 1995.5
## Variables not shown: ANNEE.OUVERTURE_mean (dbl), ANNEE.RENOVATION_mean
## (dbl), ANNEE.CHANGEMENT_mean (dbl)Mais encore ?

Voilà pour les indispensables de {dplyr}. N’ont pas été abordés ici les fusions de tables (anti_join, full_join, inner_join,semi_join,join, left_join, right_join), les opérations groupées par lignes (rowwise) et leur sélection (slice), les fonctions de comptage “raccourcies” (tally et count), le dédoublonnage avec distinct… Finalement, c’est toute une panoplie d’outils indispensables pour réaliser ce qui est supposé prendre 80% du temps des “data scientists”.
Minute DIY : Convaincus par {dplyr} ? ThinkR vous recommande d’imprimer en format A3 la cheatsheet “Manipulation de données”, de la plastifier et d’en faire des sets de table.
Chez ThinkR, nos formons à {dplyr} et au {tidyverse} dès le premier jour de formation. C’est expliqué dans notre article : Pédagogie de la formation au langage R



[…] tant que lecteur assidu de notre blog, nous sommes certains que vous avez dévoré notre billet sur le data wrangling avec {dplyr}. Dans cet exercice, nous prenions pour cas d’école un jeu de données issu de la plateforme […]
[…] étapes de la rédaction de ses articles. Vous vous en souvenez, nous vous avons déjà proposé un tuto sur la manipulation de données avec dplyr. Voici donc aujourd’hui un how-to sur la visualisation avec ggplot2 pour les […]
[…] ici, et pour une bonne raison : splarklyr a été pensé pour fonctionner parfaitement avec dplyr, et directement dans […]
[…] L’une des quêtes d’Hadley Wickham (hormis celle de la démocratisation des tidy data) est l’optimisation de la programmation avec R. Parmi ses outils, dplyr, célèbre package facilitant la manipulation de tableaux. Si vous ne le connaissez pas encore, nous en parlions sur ce blog il y a quelque temps. […]
[…] Excel comme Rstudio permet de trier et filtrer les données. Excel dans l’onglet données, Rstudio dans l’onglet filtrer sur le jeu de données visualisé ou avec la fonction filter() du package {dplyr} du {tidyverse}. […]
[…] puis écrire la requête en tidyverse. Pour en savoir plus sur le {tidyverse} rendez-vous ici, ici et là 😀 […]
[…] l’écart-type. Ce graphique est communément appelé un “barbarplot”. Vous l’avez vu dans “Utiliser la grammaire dplyr pour triturer ses données”, pour calculer une variable résumée (ici moyenne et ecart-type) séparément pour des groupes […]
[…] Enfin, pour un petit tutoriel sur {dplyr}, c’est par ici: Utiliser la grammaire dplyr pour triturer ses données […]