
Incontournables de la manipulation de données, les expressions régulières peuvent sembler ésotériques aux non-initiés, qui n’y verrons qu’une succession de points et de tirets indéchiffrables. Pourtant, une fois maitrisées, les expressions régulières deviendront un véritable super-pouvoir pour le data-wrangling. Car oui, il faut l’avouer, l’apprentissage est ardu… mais le jeu en vaut la chandelle !
Issues des théories du langage formel du milieu du 20ème siècle, les expressions régulières permettent, à l’aide d’un pattern, de détecter au sein d’une séquence de caractères une suite répondant à des critères précis. Par exemple : tous les mots qui commencent par une certaine lettre, toutes les suites contenues entre deux marqueurs, voire toutes les séquences de trois caractères en majuscule encadrées par deux points d’exclamation…. ce que vous faites de vos expressions régulières ne regarde que vous ;).

Expressions régulières, vous avez dit expressions régulières ?
 Très simplement, l’utilisation d’une expression régulière (ou regex) vous permet de parcourir une séquence de texte, afin d’en faire ressortir les motifs compatibles avec le pattern d’entrée. L’objectif ? Visualiser, modifier, ou encore supprimer…
Très simplement, l’utilisation d’une expression régulière (ou regex) vous permet de parcourir une séquence de texte, afin d’en faire ressortir les motifs compatibles avec le pattern d’entrée. L’objectif ? Visualiser, modifier, ou encore supprimer…
Une expression régulière est une suite de caractères typographiques (également appelée « caractères de substitution ») qui symbolise une autre suite caractères. Par exemple, le . fait référence à « n’importe quel caractère », et le + renvoie l’information « le caractère précédent existe une ou plusieurs fois ». Donc, vous l’aurez compris, .+ renvoie « n’importe quel caractère présent entre une fois et une infinité de fois »… une expression régulière qui renverra donc l’ensemble de votre chaine de caractère. « Pas très utile… » vous dites-vous ? Effectivement, nous ne pouvons pas vous contredire sur ce point.
Et R, dans tout ça ?
Eh oui, nous sommes ici pour vous parler de R ! Car notre logiciel favori possède bel et bien un système de gestion des expressions régulières vous permettant de manipuler les chaines de caractères — notamment avec les fonctions grep, grepl, regexpr, gregexpr, sub et gsub.
R repose sur deux librairies d’expressions régulières, appelées « extended regular expressions », renvoyant aux regex de bases, et « Perl-like », inspirée du langage Perl (accessibles via le paramètre Perl = True).
La librairie standard repose sur le standard POSIX 1003.2 (allo Wikipédia ?) définissant la syntaxe de référence des expressions régulières. Cette norme définit des classes de caractères, qui sont :
– [:alnum:] : tous les caractères alphanumériques.
– [:alpha:] : les caractères alphabétiques uniquement, en majuscule et en minuscule.
– [:blank:] : des caractères « blancs », types espace ou tabulation
– [:cntrl:] : un caractère de contrôle
– [:digit:] : un chiffre de 0 à 9
– [:graph:] : un caractère graphique, c’est-à-dire alphanumérique ou de ponctuation.
– [:lower:] : un caractère en minuscule
– [:print:] : un caractère imprimable
– [:punct:] : une ponctuation : ! » # $ % & ‘ ( ) * + , – . / : ; < = > ? @ [ \ ] ^ _ ` { | } ~.
– [:space:] : un espace (tabulation, nouvelle ligne, retour chariot…)
– [:upper:] : un caractère en majuscule
– [:xdigit:] : un caractère du système hexadécimal : 0 1 2 3 4 5 6 7 8 9 A B C D E F a b c d e f.
Vous pouvez également définir votre propre classe de caractères, en la plaçant entre crochet. Ainsi, votre fonction va rechercher tous les caractères contenus dans votre regex : par exemple, [ABC] va rechercher toutes les occurrences des trois premières lettres de l’alphabet en majuscule. À noter que si vous ouvrez votre crochet par ^, la fonction va rechercher tous les caractères sauf ceux entre crochets. Vous pouvez également utiliser le meta caractère | pour signifier OR (comme partout dans R, qui plus est) — autrement dit, [A|B] va rechercher soit A, soit B.
Pour encore plus de flexibilité, vous pouvez utiliser une série de quantifieurs, pour déterminer la position ou la répétition d’un caractère de substitution :
. : renvoie à n’importe quel caractère
^ : le caractère suivant est au début d’une chaine
$ : le caractère suivant est en fin de chaine
– ? : le caractère précédent est optionnel, et ne devra être trouvé qu’une seule fois
– * : le caractère sera trouvé zéro fois ou plus
– + : le caractère sera trouvé une fois ou plus
– {n} : le caractère sera trouvé n fois
– {n,} : le caractère sera trouvé au moins n fois
{n,m} : le caractère sera trouvé entre n et m fois.
À noter que pour utiliser les méta-caractères dans leur sens littéral, il est indispensable de les précéder d’un ou deux backslashs — autrement dit, pour rechercher un point, vous devez entrer \., non pas simplement « . ».

Un exemple ? « ^chat » va rechercher toutes les suites qui commencent par la chaine ch, suivie de la lettre a zéro ou plusieurs fois, suivie par la lettre t. Vous trouverez donc « chat », « chtis » ou encore « chaaaaaat », mais pas « pachas » ni « rachat » (promis, nous travaillons sur un meilleur exemple). Par exemple, si vous cherchez un numéro de téléphone, vous devrez utiliser l’expression « ([0-9]{2}\.){5} », qui vous renverra toutes les séries de 5 fois 2 chiffres, séparées ou non par un point (mais pas pas un tiret). Ça commence à se corser… mais vous avez compris l’idée, ne reste plus qu’à expérimenter !
Si vous entrez le paramètre perl = TRUE, vous pourrez faire appel aux expressions régulières du langage Perl. Une thématique qui n’est pas l’objet de ce billet : nous vous invitons à consulter la doc de Perl pour en savoir plus !
Et par l’exemple ?
Bien, beaucoup de théorie jusqu’ici… pas beaucoup de pratique ! Et bien, concluons sur quelques exemples ! Servons nous donc de R pour parser une page ThinkR. Avec ce court script, nous pouvons analyser la répartition des niveaux de titres d’une page web, ainsi que les liens sur la page !
library(magrittr)
#Télécharger le code HTML d'une page dans un tableau
url <- "https://thinkr.fr/guide-survie-ggplot2-datajournalistes/"
page <- readLines(con = url) %>%
as.data.frame()
names(page) <- "ligne_html"
#Index des lignes contenant un titre (balise <h1> à <h6>)
indextitres <- grep(pattern = "h[1-6]", page$ligne_html)
#Ne conserver que les lignes de titres
titres <- page[indextitres, ] %>%
as.data.frame()
#Créer un indice du niveau du titre
m <- regexpr("h[1-6]", page$ligne_html)
titres$niveau <- regmatches(page$ligne_html, m)
#Répartition des titres
library(ggplot2)
ggplot(as.data.frame(table(titres$niveau)), aes(Var1, Freq)) +
geom_bar(stat = "identity", fill = "#E3693E") +
geom_text(aes(label= as.character(Freq)), check_overlap = TRUE, size = 4) +
coord_flip() +
xlab("Niveau du titre") +
ylab("Volume") +
ggtitle(paste0("Analyse des titres de la page ", url)) +
theme_bw()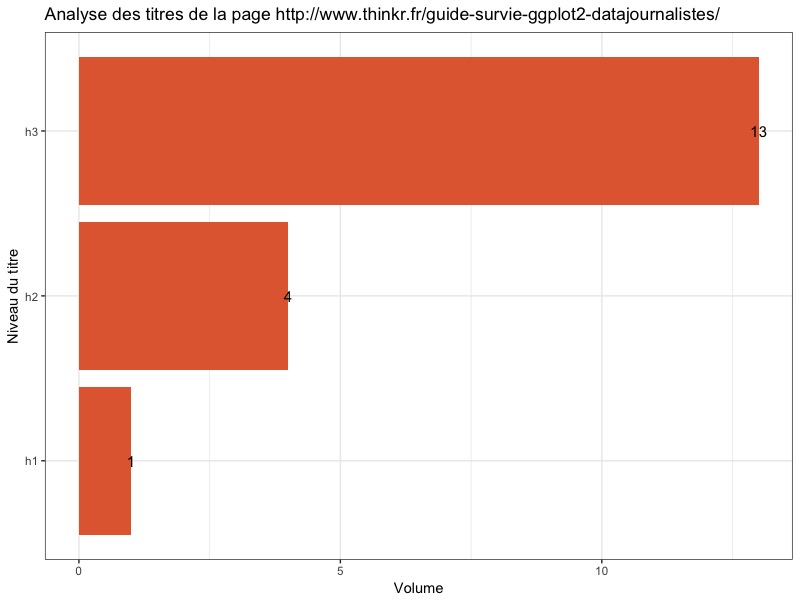
Un peu perdu dans les expressions régulières ? Ça se comprend ! Pour un coup de main, n’hésitez pas à nous en parler sur Twitter.



[…] (listes empruntées à ThinkR) […]