
En tant que fervent utilisateur de R, vous avez sûrement déjà dû vous appuyer sur cette belle communauté mondiale grâce à laquelle on a quasiment toujours une réponse à nos questions R. Mais dans le cas où, après 1h de recherche intensive, vous n’avez toujours pas réussi à solutionner votre problème, vous commencez à envisager de demander de l’aide, que ce soit sur les forums, Stackoverflow, GitHub ou encore vos workspaces Slack préférés. Et si vous n’avez pas bien préparé votre question, il y a de grandes chances qu’on vous demande si vous n’avez pas un “reprex”. Un quoi ? Un exemple reproductible. Explications…
Sommaire
Qu’est-ce-qu’un (bon) reprex, un exemple reproductible ?
Il faut bien se mettre dans la tête que lorsqu’on demande de l’aide à quelqu’un, il faut l’aider à nous aider. Maximiser la compréhension de notre problème tout en minimisant le temps nécessaire à la réponse. Parce que, vous le savez, nous sommes dans le monde de l’open source et les aidants utilisent généralement leur temps libre, soir et week-end, pour répondre à vos questions.
Cela passe, dans la majorité des cas, par fournir un exemple reproductible, c’est-à-dire un bout de code, le plus petit possible, reproduisant le problème rencontré. Et pour économiser le temps des aimables personnes qui seront prêtes à nous donner un coup de main, il y a quelques règles à respecter :
- Votre code doit fonctionner, vous devez vous assurer qu’il tourne bien chez vous avant de le poster. L’erreur, le problème, doit être reproductible avec ce code. En effet, c’est pas très classe si la réponse à votre demande ressemble à “Tu as écris
libary()au lieu delibrary().” Votre code doit contenir l’appel à tous les packages nécessaires ainsi que les objets que vous utilisez, et vous devez être capable de le faire tourner dans une nouvelle session R. - Votre code doit également être facile à lire et permettre au lecteur de comprendre immédiatement ce qu’il fait, ou est sensé faire, sans que votre sauveur·se ne soit obligé·e de le lancer. Vous pouvez également inclure une copie du résultat obtenu et/ou attendu.
- Dans le cas où il est nécessaire d’exécuter le code, ce dernier doit être facilement copiable et exécutable (les copies d’écran de votre code sont donc à bannir). Donc pas de
plot(), desummary()ou autre en plein milieu de votre code sauf si absolument nécéssaire à la compréhension de votre problématique.
Rédiger un code R lisible
Quelques règles de base de formattage de code R
Pour que votre code soit compréhensible au premier coup d’œil, des règles de bonnes pratiques en termes de syntaxe sont à suivre (et pas que dans le cas d’une demande d’aide, TOUJOURS !) :
- Indenter son code, c’est à dire ajouter des espaces lorsqu’une nouvelle ligne de code est la fin de la précédente. Les espaces vont par bloc de deux.
- Utiliser
<-au lieu de=pour assigner un nom à un objet :valeur <- 15. - Les noms des objets ne doivent contenir ni points, ni majuscules. Si le nom de votre objet est constitué de 2 mots, ces derniers doivent être séparés par un
_. Par exemple :my_data. - Les virgules doivent toujours être suivies d’un espace:
vec_tailles <- c(11, 23, 45, 67). - Ne pas mettre d’espace avant ou après des parenthèses lors de l’appel d’une fonction:
moy_tailles <- mean(vec_tailles). - Mettre un espace avant et après des parethèses dans le cadre de l’instruction
ifou des bouclesforetwhile - Toujours mettre un espace avant et après les opérateurs
<-,<,>,+,-,*,/,==, … - Ne jamais mettre un espace avant ou après les opérateurs
:,::,$,@,[ - Lorsque vous utilisez des accolades, celle qui ouvre
{doit toujours être le dernier caractère de la ligne, celle qui ferme}le premier de la ligne.
for (i in 1:10) {
if (i < 5) {
print("Trop petit !")
} else {
print("Trop grand !")
}
}- Écrire
TRUEetFALSEplutôt queTetF - Limiter le nombre de caractères par ligne (généralement 80 caractères max)
- Aller à la ligne après l’utilisation d’un
%>%
- Aller à la ligne après l’utilisation d’un
- Utiliser les guillemets
"blabla"plutôt que les apostrophes'blabla'pour les chaînes de caractères, excepté si le texte en question contient déjà des guillemets :'il dit "blabla"'- Notez que vous pouvez “échapper” un guillemet interne à une chaîne de caractères :
"il dit \"blabla\""
- Notez que vous pouvez “échapper” un guillemet interne à une chaîne de caractères :
Ces règles sont les indispensables. Mais si vous souhaitez un code atteignant la perfection, LA référence, c’est le guide de style du tidyverse: https://style.tidyverse.org/index.html
Utiliser les outils d’aide au reformatage du code
Certaines de ces règles ne font pas toujours partie de nos habitudes de code (par exemple, j’écris toujours if(condition) au lieu de if (condition)). Dans ce cas, le package {styler} peut faire le boulot à notre place.
# Installation du package
install.packages("styler")
# Utilisation sur fichier de votre projet
styler::style_file(path = "mon-analyse.Rmd")J’ai par exemple ce code qui me fait saigner des yeux (c’est un peu la version R du “sa va ?” si on peut dire) et que je souhaite mettre en forme :
maFonctionSomme=function (a,b){
if(is.numeric(a) & is.numeric(b)){
a+b} else{print('Erreur : a et b doivent être numériques')
NULL}}Si vous travaillez avec RStudio, vous pouvez utiliser la fonction de base de RStudio pour remettre en forme votre code avec la combinaison : Ctrl + Shift + A. Sinon, vous utilisez l’addin (le Complément) de {styler} (qui apparaîtra dans votre liste d’addins après installation du package), que ce soit pour des bouts de code ou des projets entiers.
Je sélectionne les lignes concernées, et applique ensuite l’addin :
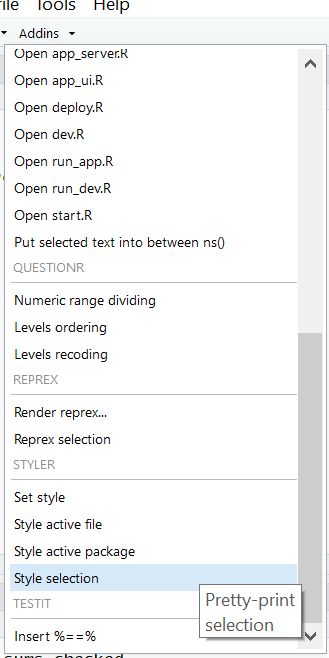
Et comme par magie, mon code a été modifié, et est maintenant beaucoup plus lisible :
maFonctionSomme <- function(a, b) {
if (is.numeric(a) & is.numeric(b)) {
a + b
} else {
print("Erreur : a et b doivent être numériques")
NULL
}
}Le nom de la fonction n’a quant à lui malheureusement pas été modifié car ce changement pourrait avoir une incidence dans le reste de mon code. Mais de toutes façons, à partir de maintenant vous écrirez le nom de cette fonction directement ainsi : ma_fonction_somme. C’est ce qu’on appelle l’écriture “snake case”. C’est celle qui est recommandée pour la lisibilité de votre code R. *_Notez que R est sensible à la casse, MaFonction est différent de maFonction, donc pour réduire les problèmes, on met tout en minuscule avec des mots bien espacés, comme lorsqu’on écrit en français (le _ en plus). D’où le “snake_case” plutôt que le “CamelCase”.
Partager les données de votre exemple sur un forum ou ailleurs
Le “repr” de “reprex”, c’est pour reproductible, vous devez donc faire attention aux données que vous utilisez dans votre exemple, pas de read_table(), readRDS(), car les aidants n’auront pas accès à vos données. Vous pouvez envisager de mettre les données téléchargeables sur Internet, mais (1) cela peut s’avérer embêtant si le lien doit être modifié ou supprimé dans le futur, (2) cela fait une étape de plus pour vos aidants et (3) ils·elles n’ont peut-être pas une connexion Internet permettant de télécharger rapidement votre gros fichier.
Deux bonnes options sont envisageables : utiliser un jeu de données existant dans R ou partager une partie de ses données (ou données similaires).
Créer un exemple avec un jeu de données présent dans R
Utiliser un jeu de données de r-base comme mtcars, iris, ou autres données du package {datasets} par exemple. Dans ce cas, peut-être que seul un échantillons des données sera nécessaire, en fonction de votre problématique. Pour créer un sous-ensemble, on pourra utiliser des fonctions comme head(), tail(), ou encore sample(). Attention, je vous rappelle que votre exemple doit être reproductible, donc si vous appelez une fonction faisant appel à l’aléa, comme c’est le cas pour sample(), il sera nécessaire de fixer la graine de l’aléa via l’utilisation de la fonction set.seed().
# Mon problème apparaît aussi avec mtcars
mes_data <- head(mtcars)
# J'ai des zéro partout, pourquoi?
mes_data * FALSEPartager une partie de ses données
Vous pouvez partager directement une partie de vos données ou créer vous-même des données similaires à vos données directement dans votre script. Et là, attention, je vous vois venir avec vos gros sabots ! On ne se lance pas tête baissée dans la création d’un énorme data.frame illisible, genre :
data_bad <- data.frame(
category = c("2015-01-01", "2015-01-02", "2015-01-03",
"2015-01-04", "2015-01-05", "2015-01-06",
"2015-01-07", "2015-01-08", "2015-01-09",
"2015-01-10", "2015-01-11", "2015-01-20"),
open = c(136.65, 135.26, 132.90, 134.94, 136.76, 131.11,
123.12, 128.32, 128.29, 122.74, 117.01, 122.01),
close = c(136.4, 131.8, 135.2, 135.0, 134.0, 126.3,
125.0, 127.7, 124.0, 119.9, 117.0, 122.0),
jour = c("lundi", "mardi", "mercredi", "jeudi", "vendredi", "samedi", "dimanche",
"lundi", "mardi", "mercredi", "jeudi", "vendredi"),
stringsAsFactors = FALSE)Compliqué de visualiser ces données non ? Pour respecter notre lecteur, et lui permettre comme je le disais plus haut de se faire rapidement une idée claire de la question que l’on pose, on préfèrera la construction des données ligne par ligne, possible grâce à la fonction tribble() du package {tibble} :
data_good <- tibble::tribble(
~category, ~open, ~close, ~jour,
"01/01/2015", 136.65, 136.4, "lundi",
"02/01/2015", 135.26, 131.8, "mardi",
"03/01/2015", 132.9, 135.2, "mercredi",
"04/01/2015", 134.94, 135, "jeudi",
"05/01/2015", 136.76, 134, "vendredi",
"06/01/2015", 131.11, 126.3, "samedi",
"07/01/2015", 123.12, 125, "dimanche",
"08/01/2015", 128.32, 127.7, "lundi",
"09/01/2015", 128.29, 124, "mardi",
"10/01/2015", 122.74, 119.9, "mercredi",
"11/01/2015", 117.01, 117, "jeudi",
"20/01/2015", 122.01, 122, "vendredi"
)Bien mieux, non ? Et en plus, les colonnes sont super bien alignées ! Alors non, je ne me suis pas amusée à faire les espaces à la main. J’ai utilisé un autre petit addin RStudio magique, qui nous vient du package {datapasta}. Ce package va particulièrement vous intéresser dans le cas où vous avez des données comme celles de mon exemple ci-dessus, ou dans un fichier Excel ou csv, ou déjà dans R. Ci-dessous la marche à suivre selon les cas, après avoir installé le package {datapasta} :
- Cas 1 : mes données sont dans un fichier Excel
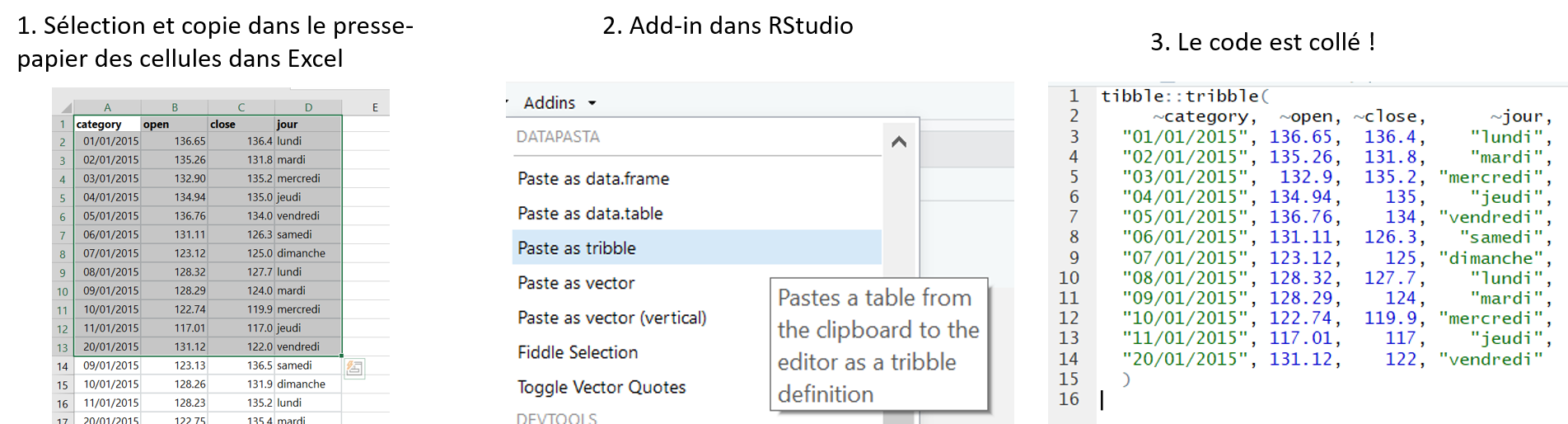
- Cas 2 : mes données sont dans R. Il vous faut appeler la fonction
dpasta()
library(dplyr)
head(iris) %>%
as_tibble() %>%
datapasta::dpasta()Ce code sera automatiquement remplacé par :
tibble::tribble(
~Sepal.Length, ~Sepal.Width, ~Petal.Length, ~Petal.Width, ~Species,
5.1, 3.5, 1.4, 0.2, "setosa",
4.9, 3, 1.4, 0.2, "setosa",
4.7, 3.2, 1.3, 0.2, "setosa",
4.6, 3.1, 1.5, 0.2, "setosa",
5, 3.6, 1.4, 0.2, "setosa",
5.4, 3.9, 1.7, 0.4, "setosa"
)Oui, c’est beau !
Notez qu’en r-base, sans charger de package donc, vous pouvez utiliser la fonction dput() sur un échantillon de vos données sur lesquelles vous reproduisez votre problème. Vous verrez que le code est encore moins lisible, mais il garde son caractère reproductible.
# Je ne peux pas vous montrer mes données nommé "ouvertures"
# mais voici un echantillon des premieres lignes
# que j'ai créé avec `dput(head(ouvertures))`
dput(head(ouvertures))## structure(list(category = c("2015-01-01", "2015-01-02", "2015-01-03",
## "2015-01-04", "2015-01-05", "2015-01-06"), open = c(136.65, 135.26,
## 132.9, 134.94, 136.76, 131.11), close = c(136.4, 131.8, 135.2,
## 135, 134, 126.3), jour = c("lundi", "mardi", "mercredi", "jeudi",
## "vendredi", "samedi")), row.names = c(NA, 6L), class = "data.frame")# Je suis l'aidant et je copie votre code directement
ouvertures <- structure(list(category = c("2015-01-01", "2015-01-02", "2015-01-03",
"2015-01-04", "2015-01-05", "2015-01-06"), open = c(136.65, 135.26,
132.9, 134.94, 136.76, 131.11), close = c(136.4, 131.8, 135.2,
135, 134, 126.3), jour = c("lundi", "mardi", "mercredi", "jeudi",
"vendredi", "samedi")), row.names = c(NA, 6L), class = "data.frame")
# Voyons a quoi cela ressemble
ouvertures## category open close jour
## 1 2015-01-01 136.65 136.4 lundi
## 2 2015-01-02 135.26 131.8 mardi
## 3 2015-01-03 132.90 135.2 mercredi
## 4 2015-01-04 134.94 135.0 jeudi
## 5 2015-01-05 136.76 134.0 vendredi
## 6 2015-01-06 131.11 126.3 samediÇa fait le job, mais ce n’est pas lisible tant qu’on n’a pas importé le code. Je vous le rappelle, les aidants prennent de leur temps libre, dans beaucoup de cas ils pourront répondre à votre question sans même tester votre code. Pensez aussi qu’ils peuvent être dans le bus, à regarder votre question sur leur smartphone, sans pouvoir tester. Ils peuvent peut-être quand même vous aider!
De l’exemple parfait à la publication parfaite
… il n’y a qu’un pas ! Ou plutôt, qu’un package supplémentaire : {reprex}. C’est un package interactif qui va nous permettre d’inclure le code R à notre question, sans trop faire d’efforts, avec une coloration syntaxique adéquate, et tout ça grâce à la fonction du même nom : reprex().
Notez que sur GNU Linux, vous devrez installer xclip. Par exemple, sur Ubuntu, vous devrez faire sudo apt install xclip.
Un exemple d’utilisation de {reprex}
La manipulation est la suivante: une fois votre code remplissant toutes les conditions du bon reprex, sélectionnez toutes les lignes du code, copiez-le dans le presse-papier (Ctrl + C), et tapez dans la console R: reprex(), puis Entrée.
Je copie par exemple le code suivant, et appelle reprex() dans la console :
my_iris <- tibble::tribble(
~Sepal.Length, ~Sepal.Width, ~Petal.Length, ~Petal.Width, ~Species,
5.1, 3.5, 1.4, 0.2, "setosa",
4.9, 3, 1.4, 0.2, "setosa",
4.7, 3.2, 1.3, 0.2, "setosa",
4.6, 3.1, 1.5, 0.2, "setosa",
5, 3.6, 1.4, 0.2, "setosa",
5.4, 3.9, 1.7, 0.4, "setosa"
)
summary(my_iris)Le Viewer Rstudio donne alors un aperçu du rendu de votre exemple dans votre question :
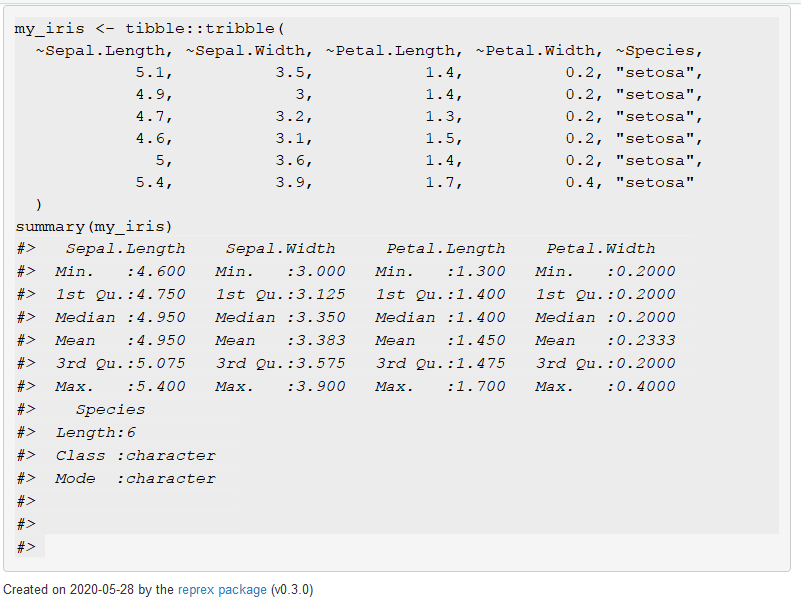
my_iris <- tibble::tribble(
~Sepal.Length, ~Sepal.Width, ~Petal.Length, ~Petal.Width, ~Species,
5.1, 3.5, 1.4, 0.2, "setosa",
4.9, 3, 1.4, 0.2, "setosa",
4.7, 3.2, 1.3, 0.2, "setosa",
4.6, 3.1, 1.5, 0.2, "setosa",
5, 3.6, 1.4, 0.2, "setosa",
5.4, 3.9, 1.7, 0.4, "setosa"
)
summary(my_iris)
#> Sepal.Length Sepal.Width Petal.Length Petal.Width
#> Min. :4.600 Min. :3.000 Min. :1.300 Min. :0.2000
#> 1st Qu.:4.750 1st Qu.:3.125 1st Qu.:1.400 1st Qu.:0.2000
#> Median :4.950 Median :3.350 Median :1.400 Median :0.2000
#> Mean :4.950 Mean :3.383 Mean :1.450 Mean :0.2333
#> 3rd Qu.:5.075 3rd Qu.:3.575 3rd Qu.:1.475 3rd Qu.:0.2000
#> Max. :5.400 Max. :3.900 Max. :1.700 Max. :0.4000
#> Species
#> Length:6
#> Class :character
#> Mode :character
#>
#>
#>
Created on 2020-05-28 by the [reprex package](https://reprex.tidyverse.org) (v0.3.0)Ajouter un graphique à ma publication
Dans le cas où votre question contient un graph (statique), l’image sera automatiquement chargée sur le site web imgur.com. L’inclusion de cette image sera présente dans le texte que vous aurez à copier dans votre message. Par exemple :
library(ggplot2)
theme_set(theme_classic())
# Histogram on a Continuous (Numeric) Variable
ggplot(mpg, aes(displ)) +
geom_histogram(
aes(fill = class),
binwidth = .1, col = "black", size = 0.1
) +
scale_fill_brewer(palette = "Spectral") +
labs(
title = "Histogram with Auto Binning",
subtitle = "Engine Displacement across Vehicle Classes"
)Après avoir suivi le process usuel (copie + reprex()), notre aperçu s’affiche correctement :
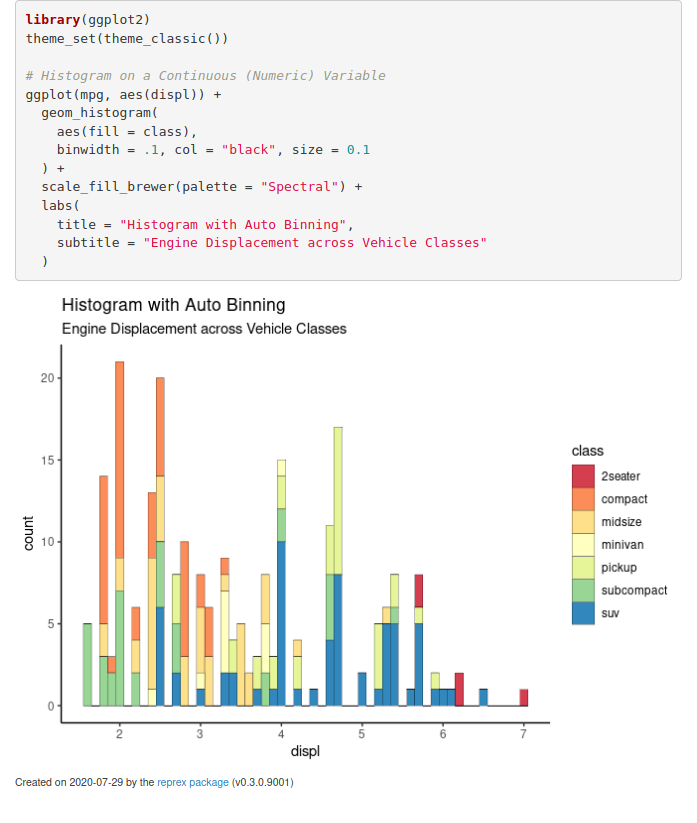
Et voici le code obtenu :
``` r
library(ggplot2)
theme_set(theme_classic())
# Histogram on a Continuous (Numeric) Variable
ggplot(mpg, aes(displ)) +
geom_histogram(
aes(fill = class),
binwidth = .1, col = "black", size = 0.1
) +
scale_fill_brewer(palette = "Spectral") +
labs(
title = "Histogram with Auto Binning",
subtitle = "Engine Displacement across Vehicle Classes"
)
```

<sup>Created on 2020-07-29 by the [reprex package](https://reprex.tidyverse.org) (v0.3.0)</sup>Notez le
(que vous ne devez pas changer) ! D’ailleurs, vous pouvez vous-même aller voir cette magnifique image à cette adresse : https://i.imgur.com/qkqq9r0.png
Le paramètre venue
Il s’agit d’un paramètre important si vous souhaitez publier votre message ailleurs que sur GitHub. Il peut prendre les valeurs suivante, selon la destination de votre exemple :
venue = "gh": c’est la valeur par défaut, pour publier votre reprex sur GitHubvenue = "so": Stack Overflowvenue = "ds": communauté RStudiovenue = "r": une sortie plus R-friendly (les commentaires contenant les sorties seront inclus). Parfait pour une utilisation dans un code snippet dans Slack !venue = "rtf": Rich Text Format (expérimental)venue = "html": inclure directement dans un document HTML.
Concrètement, si je veux poster sur Stack Overflow, ça se passe comment ? Eh bien c’est comme précédemment : on copie le code de notre reprex, et on appelle la fonction dans la console, en spécifiant le paramètre venue : reprex(venue = "so"). Sur l’exemple précédent, cela donne :
<!-- language-all: lang-r -->
library(ggplot2)
theme_set(theme_classic())
# Histogram on a Continuous (Numeric) Variable
ggplot(mpg, aes(displ)) +
geom_histogram(
aes(fill = class),
binwidth = .1, col = "black", size = 0.1
) +
scale_fill_brewer(palette = "Spectral") +
labs(
title = "Histogram with Auto Binning",
subtitle = "Engine Displacement across Vehicle Classes"
)

<sup>Created on 2020-07-29 by the [reprex package](https://reprex.tidyverse.org) (v0.3.0)</sup>Les autres paramètres de la fonction reprex()
Je ne vous citerai ici que ceux qui me semblent intéressants, mais libre à vous d’aller fouiller l’aide de la fonction ?reprex.
advertise:TRUEpar défaut, ajout ou non de la mention “Created on 2020-05-29 by the reprex package (v0.3.0)”si:FALSEpar défaut, ajout ou non de l’information donnée pardevtools::session_info()ousessionInfo()à la fin de votre reprex. Les versions des packages que vous utilisez peuvent être important pour répondre à votre problème. Cet ajout peut vous être demandé.style:FALSEpar défaut. Si ce paramètre est mis àTRUE, il permet d’appliquer directement la fonctionstyle_text()du package{styler}dont je vous parlais en début d’article et qui permet une mise en forme propre de votre code.show: affichage ou non de l’aperçu de votre message prêt à poster dans le Viewer RStudio
Les addins RStudio pour le package {reprex}
Le package {reprex} vient doté de deux addins :
- Render reprex… qui ouvre une fenêtre offrant une solution de clic-bouton pour créer votre sortie :
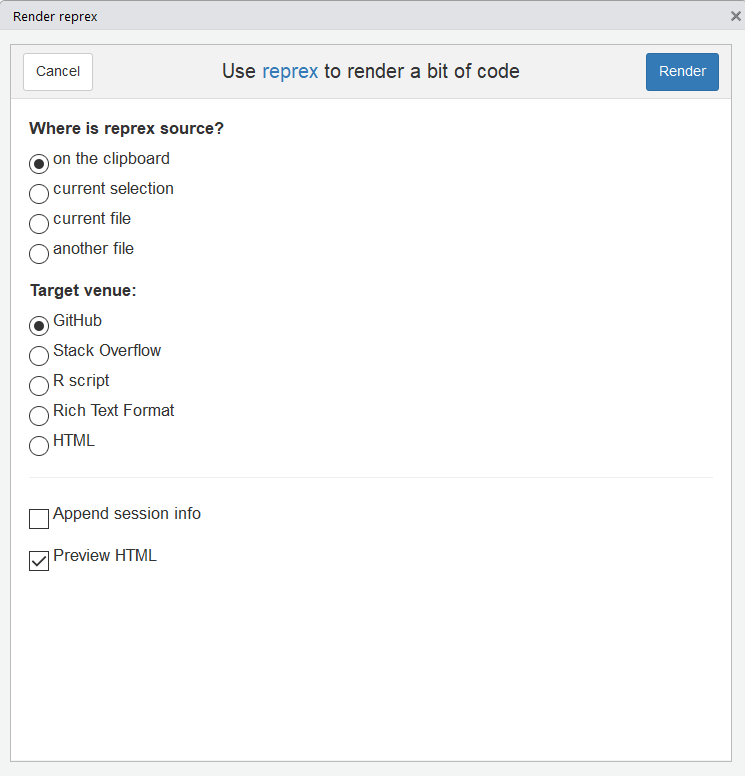
- Reprex selection qui fonctionne comme les addins que nous avons vus précedemment : sélectionner le bout de code que vous souhaitez ajouter, sans le copier, et cliquer sur cet addin au lieu de taper
reprex()dans la console. Cela peut être très utile si vous avez besoin de faire beaucoup de reprex et que vous avez créé un raccourci clavier pour cet addin. Attention cependant aux paramètres : les valeurs par défaut seront appliquées.
Note : pour modifier les raccourcis claviers dans RStudio, suivez le chemin : Tools > Modify Keyboard Shortcuts et tapez ‘addin’ dans la barre de recherche pour afficher et modifier les raccourcis correspondants. On vous en parle plus longuement dans “Profiter pleinement de RStudio (et de ses nouveautés) et programmer comme l’éclair”.
Ajouter la version de R
C’est peut-être un détail pour vous…
… mais dans certains cas, ça veut dire beaucoup. N’oubliez pas d’ajouter à votre exemple la version de R que vous utilisez, ainsi que celles des packages nécessaires au bon fonctionnement de votre reprex maintenant tout beau tout propre ! On l’a vu à l’occasion de notre article sur la nouvelle version de {dplyr}, les fonctions et leurs paramètres peuvent être modifiés, donc attention !
À vos reprex !
Vous savez maintenant comment présenter votre code pour demander de l’aide. On vous retrouvera peut-être sur le forum Community de RStudio (en anglais), dans les questions R de Stack Overflow (en anglais) ou dans les forums développez.net (en français).
Ceci étant dit, dans tous les cas, pensez à chercher avant si la réponse n’existe pas déjà. Pour cela, copier-coller directement votre message d’erreur dans votre moteur de recherche préféré, ou écrivez-y votre question en toutes lettres, en français ou en anglais, vous trouverez probablement votre bonheur. Vous pouvez aussi suivre le guide de Maëlle Salmon: “Where to get help with your R question?”.
Article rédigé par Elena Salette, avec la participation de Sébastien Rochette.




Laisser un commentaire