
À moins d’être resté enfermé dans un frigo ces cinq dernières années, vous avez forcément entendu parler de machine learning. Et pour cause : les algorithmes “d’apprentissage automatique” (pour les amoureux de la langue de Molière) ont progressivement envahi tous les secteurs : finance, marketing, web… La liste est longue ! Zoom sur le machine learning avec R.
Sommaire
De quoi parle-t-on ?
Nous avons déjà plusieurs fois abordé la question du machine learning sur ce blog, notamment lors de nos billets sur le deep learning et sur les réseaux de neurones. Promis, nous n’allons pas vous rabâcher la définition encore et encore – il vous suffit simplement de vous rappeler que l’apprentissage automatique regroupe l’ensemble des techniques qui permettent d’évaluer des données nouvelles et de réaliser une prédiction basée sur les connaissances tirées de données anciennes.
Dans ce billet, nous allons vous parler de concret – aka : comment mettre en place votre premier algorithme de machine learning avec R.
Machine learning 101 : la régression linéaire simple
Le premier algorithme de machine learning que nous verrons ici est la régression linéaire simple, ou univariée. Nous commençons par cet algo pour une bonne raison : si vous débutez en apprentissage automatique, il s’agit d’un des modèles les plus accessibles – à la fois conceptuellement car facile à comprendre, mais aussi simple à mettre en place.
Alors, qu’est-ce que c’est ? Cette régression linéaire est un algorithme de machine learning qui consiste à trouver la meilleure fonction permettant de définir une variable de sortie (l’élément à prédire) à partir d’une une seule et unique variable explicative en entrée (le prédicteur) — c’est pour cette raison que l’on parle de régression univariée, à l’inverse des modèles multivariés, qui prennent en compte plusieurs variables explicatives. Graphiquement, il s’agit de trouver la meilleure droite possible pouvant expliquer un modèle (x, y). Cette fonction est de la forme Y = BO + XB1 + E, où Y est la réponse, BO l’ordonnée à l’origine, X la variable explicative, B1 la pente (la valeur d’évolution de X lorsqu’il augmente d’une unité), et enfin E, l’erreur statistique.
Concrètement, cela peut-être, par exemple, prédire le prix d’un appartement en fonction de sa surface en se basant sur les prix actuels, prédire l’augmentation d’un chiffre d’affaires en fonction des dépenses publicitaires, etc. Dans les faits, il est rare de construire des modèles solides avec une seule variable explicative. Cependant, c’est un incontournable pour se lancer !
Votre premier algorithme de machine learning
Tout problème de machine learning commence par… un jeu de données (mais vous vous en seriez douté). L’exercice d’aujourd’hui ? Prédire le volume de pages vues en fonction du nombre de visiteurs du site http://metropole.rennes.fr/, en se basant sur les données de 2016.
library(tidyverse)
rennes <- read_csv2("https://data.rennesmetropole.fr/explore/dataset/statistiques-de-frequentation-du-site-de-rennes-ville-et-metropole/download/?format=csv&timezone=Europe/Berlin&use_labels_for_header=true") %>%
na.omit()
glimpse(rennes)
## Observations: 402
## Variables: 3
## $ Date 2017-01-04, 2017-01-06, 2017-01-17, 2017-01-20, ...
## $ Utilisateurs 3888, 3147, 3826, 3120, 3800, 2161, 1912, 2886, 4...
## $ Pages vues 11071, 9450, 10686, 9325, 10951, 6235, 5434, 8958...
plot(rennes)
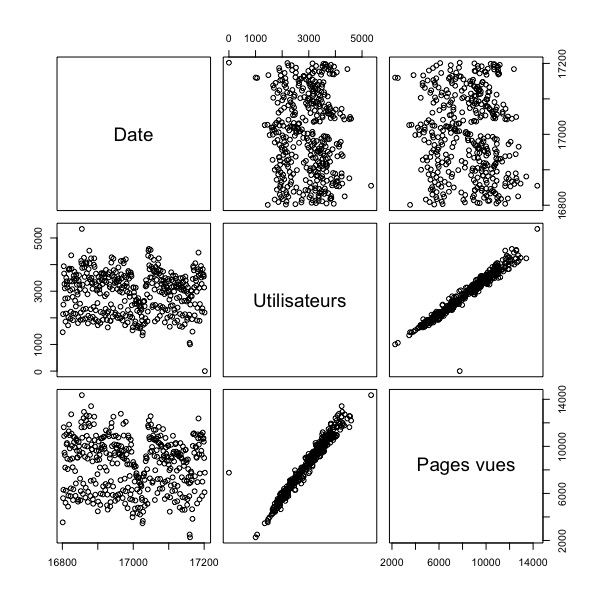
Ici, nous visualisons clairement une relation entre utilisateurs et pages vues (chaque point représentant un jour de l’année). Construisons maintenant notre modèle linéaire, qui se définie comme model <- lm(variableàexpliquer ~ variableexplicative, data = jeudedonnées).
Un peu de prédiction
Créons notre modèle linéaire avec la fonction lm().
model <- lm(`Pages vues` ~ Utilisateurs, data = rennes)
#Ce modèle est-il bon ?
summary(model)$r.squared
## [1] 0.9419583
Nous n’entrerons pas dans les détails statistiques de l’élément r.squared – rappelez-vous seulement que plus cet indicateur est proche de 1, plus l’on peut considérer que notre modèle linéaire est bon.
Bien, maintenant que nous avons notre modèle, lançons-nous dans la prédiction ! Comment ça marche ? Tout simplement avec la fonction predict(). Voici comment cette dernière se construit : prediction <- predict(modèle, jeudedonnéesàprédire).
#Un nombre de visiteurs fictifs
new_data <- data.frame(Utilisateurs = c(100, 1000, 5000, 10000))
prediction <- predict(model, new_data) %>%
as.data.frame() %>%
cbind(new_data, .)
prediction
## Utilisateurs .
## 1 100 378.7554
## 2 1000 2933.0149
## 3 5000 14285.2796
## 4 10000 28475.6104
Résultat ? Notre modèle prédit 378 pages vues, si 100 utilisateurs viennent sur le site, 2933 pages vues si 1000 utilisateurs visitent, etc. Voilà, nous avons construit notre premier modèle de machine learning, nous permettant d’évaluer le nombre de pages vues sur le site de Rennes Métropole en fonction du volume de visiteurs. Vous vous en doutez, il ne s’agit ici que d’un premier pas ! Les algorithmes de machine learning sont, dans la pratique, plus complexes, et il est (très) rare de construire des modèles avec une seule variable explicative. Mais maintenant que vous avez compris comment cela fonctionne, les modèles un peu plus poussés sont à portée de code !
Envie d'en découvrir plus sur le machine learning avec R ? Restez connecté ! Après ce premier billet d'introduction (très) simple, nous reviendrons très bientôt ici sur d'autres méthodes d'apprentissage automatique — notamment de classification et de clustering.



[…] assidus de notre blog, vous n’avez pas manqué notre premier billet sur le machine learning, traitant de la régression linéaire. Mais voilà, depuis ce jour, une […]