
La « dream team » du tidyverse se compose de 6 packages, qui se lancent avec library(tidyverse) : {ggplot2}, {dplyr}, {tidyr}, {reader}, {purrr} et {tibble}. Pourtant, si on lit dans les petites lignes, le tidyverse regorge d’autres outils incontournables. Parmi eux : {forcats}, sujet de notre billet d’aujourd’hui.
À ne pas confondre avec {forecast} (pour travailler avec des séries temporelles), {forcats} se destine à une gestion simplifiée des facteurs, autrement dit des valeurs catégorielles… « a package [for cat]egorical variables ». (C’est bon, vous l’avez ? 😉 ). Sans oublier : il s’agit d’une anagramme de factors !
Sommaire
R et les facteurs
Bon, commençons par rappeler rapidement ce qu’est un facteur : il s’agit d’un type de variable qui peut prendre comme valeur un nombre fini de modalités. Autrement dit, une variable est considérée comme facteur lorsqu’elle ne peut pas être mesurée directement par un nombre continu : par exemple, une couleur, un métier, une ville, un statut marital… Un facteur peut être ordonné (non satisfait, moyennement satisfait, satisfait, très satisfait) ou non (Paris, Rennes, Montpellier).
L’usage des facteurs en statistiques n’est pas d’hier : vous vous en doutez donc, son utilisation dans R date également. C’est d’ailleurs le comportement historique de R : traiter les chaînes de caractères comme des facteurs, avec l’option stringsAsFactors, câblée sur TRUE par défaut. Car oui, « back in the days », ce comportement faisait sens : en statistiques, les strings sont majoritairement des facteurs. Si nous devons creuser un peu plus, nous pouvons aussi nous rappeler que, en background, R transforme les facteurs en représentations numériques : par exemple, « marié / non marié » sera converti en 1 et 2. Ce qui, en bout de course, fait gagner de la place, les chiffres demandant moins de bytes que les chaînes de caractères :
object.size(1)
48 bytes
object.size("une_modalite_encode_avec_un_nom_super_long")
136 bytes
Un comportement qui en fait aujourd’hui bondir plus d’un, et ne manque pas de faire couler de l’encre, tant dans la littérature que sur les blogs et sur Twitter. Mais bref, nous ne sommes pas ici pour relancer le débat, et avouons le, en stats, les facteurs sont indispensables. Alors, comment les manipuler dans le tidyverse ?
forcats pas-à-pas
# Si besoin
# install.packages("forcats")
# ou, pour être plus tranquille :
# install.packages("tidyverse")
library(forcats)
library(tidyverse)
Jouons d’abord avec le jeu de données storms, disponible dans {dplyr}. Nativement, les datasets de ce package sont des tibbles, et les colonnes contenant des strings sont des caractères. C’est le cas par exemple de status.
storms %>%
count(status)
# A tibble: 3 x 2
status n
1 hurricane 3091
2 tropical depression 2545
3 tropical storm 4374
On voit ici qu’il s’agit d’une variable factorielle. Bien, « time to change »!
as_factor
Première fonction du package, as_factor, utilisée pour transformer un vecteur en facteur. Quelle différence avec {base} ? La version {forcats} créer les niveaux du facteur en fonction de leur apparition dans le jeu de données, à l’inverse de {base}, qui trie en fonction de la configuration de votre locale (et donc, peut donner lieu à des différences d’une machine à l’autre).
Par exemple :
x <- c("a", "z", "g")
as_factor(x)
[1] a z g
Levels: a z g
as.factor(x)
[1] a z g
Levels: a g z
Ici, on voit bien que le premier imprime un ordre a z g, là où le second affiche a g z, en fonction de l'ordre alphabétique (qui n'est pas le même partout, rappelons-le).
storms <- storms %>%
mutate(status = as_factor(status))
Bon, nous n'avons pas assez de modalités (3), pour pouvoir vraiment manipuler des facteurs… Testons plutôt le jeu de données natif de {forcats}, gss_cat, contenant un sample du General Social Survey.
fct_anon
Si, par exemple, vous bossez dans la recherche médicale, l'anonymisation est primordiale (on vous en parlait déjà ici : forcément, il y a une fonction pour ça !
gss_cat %>%
mutate(relig = fct_anon(relig)) %>%
group_by(relig) %>%
count
# A tibble: 15 x 2
# Groups: relig [15]
relig n
1 02 93
2 03 689
3 04 15
4 05 71
5 06 5124
6 07 224
7 08 32
8 09 10846
9 10 104
10 11 3523
11 12 109
12 13 388
13 14 95
14 15 23
15 16 147
fct_c
Vous avez utilisé R plus d'une journée, vous connaissez forcément l'opérateur c, indispensable pour concaténer des vecteurs les uns avec les autres. L'équivalent dans {forcats} est fct_c, et vous permet de concaténer les facteurs de la même manière, là où {base} vous renvoie la version "integer" de vos facteurs :
fac_a <- factor(c("a", "b"))
fac_b <- factor(c("c", "d"))
c(fac_a, fac_b)
[1] 1 2 1 2
fct_c(fac_a, fac_b)
[1] a b c d
Levels: a b c d
fct_collapse
Cette fonction transforme les niveaux d'un facteur, soit pour les renommer soit pour les regrouper :
gss_cat %>%
mutate(relig = fct_collapse(relig,
no_answer = c("No answer", "Don't know", "Not applicable", "None"))) %>%
group_by(relig) %>%
count
# A tibble: 13 x 2
# Groups: relig [13]
relig n
1 no_answer 3631
2 Inter-nondenominational 109
3 Native american 23
4 Christian 689
5 Orthodox-christian 95
6 Moslem/islam 104
7 Other eastern 32
8 Hinduism 71
9 Buddhism 147
10 Other 224
11 Jewish 388
12 Catholic 5124
13 Protestant 10846
fct_count
Une fonction pour compter les entrées dans un facteur. Un équivalent à table de {base} :
gss_cat %>%
pull(marital) %>%
fct_count()
# A tibble: 6 x 2
f n
1 No answer 17
2 Never married 5416
3 Separated 743
4 Divorced 3383
5 Widowed 1807
6 Married 10117
fct_drop
Une fonction qui est là pour vous débarrasser des niveaux de facteurs inutilisés. La différence avec droplevels ? Les valeurs NA ne sont pas retirée ! Vous pouvez aussi sélectionner les modalités à faire disparaître.
gss_status <- factor(gss_cat$marital,
levels =c("No answer", "Never married", "Separated", "Divorced","Widowed", "Married", "plop", "ploum"))
gss_status %>% fct_count()
# A tibble: 8 x 2
f n
1 No answer 17
2 Never married 5416
3 Separated 743
4 Divorced 3383
5 Widowed 1807
6 Married 10117
7 plop 0
8 ploum 0
gss_status %>% fct_drop() %>% fct_count()
# A tibble: 6 x 2
f n
1 No answer 17
2 Never married 5416
3 Separated 743
4 Divorced 3383
5 Widowed 1807
6 Married 10117
# Avec only, vous pouvez ne droper que certains facteurs
gss_status %>% fct_drop(only = "plop") %>% fct_count()
# A tibble: 7 x 2
f n
1 No answer 17
2 Never married 5416
3 Separated 743
4 Divorced 3383
5 Widowed 1807
6 Married 10117
7 ploum 0
fct_expand
Vous avez besoin d'ajouter de nouveaux niveaux à votre facteur ? Direction fct_expand (oui oui, exactement ce que nous venons de faire juste au-dessus) :
gss_cat %>%
pull(marital) %>%
fct_expand("plop", "ploum") %>%
fct_count()
# A tibble: 8 x 2
f n
1 No answer 17
2 Never married 5416
3 Separated 743
4 Divorced 3383
5 Widowed 1807
6 Married 10117
7 plop 0
8 ploum 0
fct_explicit_na
Cette fonction vous permet de rendre les NA explicites, autrement dit de les faire apparaître dans votre jeu de données. Ce que ne fait pas table, qui par défaut n'affiche pas les NA : explicit_NA les transforme en (Missing), afin de les faire ressortir dans le classement.
gss_cat %>%
pull(marital) %>%
fct_c(factor(x = c(NA,NA,NA))) %>%
table()
No answer Never married Separated Divorced Widowed
17 5416 743 3383 1807
Married
10117
gss_cat %>%
pull(marital) %>%
fct_c(factor(x = c(NA,NA,NA))) %>%
fct_explicit_na() %>%
table()
No answer Never married Separated Divorced Widowed
17 5416 743 3383 1807
Married (Missing)
10117 3
(Missing) est la valeur par défaut donnée aux données manquantes, mais rassurez-vous : vous pouvez modifier leur petit nom :
gss_cat %>%
pull(marital) %>%
fct_c(factor(x = c(NA,NA,NA))) %>%
fct_explicit_na(na_level = "(Pauvres petites NA) ") %>%
table()
No answer Never married Separated
17 5416 743
Divorced Widowed Married
3383 1807 10117
(Pauvres petites NA)
3
fct_infreq et fct_inorder
Ces deux fonctions sont là pour réordonner les facteurs selon leur fréquence, ou en fonction de leur apparition dans le jeu de données. Le paramètre ordered indique si oui ou non, les facteurs sont... ordonnés (unbielievable, n'est-il pas ? 😉 ).
gss_cat %>%
pull(marital)
...
Levels: No answer Never married Separated Divorced Widowed Married
gss_cat %>%
pull(marital) %>%
fct_infreq()
...
Levels: Married Never married Divorced Widowed Separated No answer
gss_cat %>%
pull(marital) %>%
fct_inorder(ordered = TRUE)
...
Levels: Never married < Divorced < Widowed < Married < Separated < No answer
fct_lump
Vous avez besoin de grouper les facteurs les plus communs ? Les plus rares ? Il y a une fonction pour ça ! Laissez-nous vous présenter fct_lump :
# Avec n positif, la fonction conserve les n facteurs les plus courants
gss_cat %>%
pull(relig) %>%
fct_lump(n = 2) %>%
levels()
[1] "Catholic" "Protestant" "Other"
# Avec n négatif, la fonction conserve les n facteurs les moins courants
gss_cat %>%
pull(relig) %>%
fct_lump(n = -2) %>%
levels()
[1] "Don't know" "Not applicable" "Other"
# Avec prop, vous conservez les valeurs qui apparaissent au moins "prop of the time", c'est-à-dire que prop = 0.2 conserve les facteurs qui représentent au moins 20% de votre vecteur.
gss_cat %>%
pull(relig) %>%
fct_lump(prop = 0.05) %>%
levels()
[1] "None" "Catholic" "Protestant" "Other"
# Avec un prop négatif, on définit une marge maximale d'apparition. À noter que vous pouvez définir un "Other" à votre gout avec other_level
gss_cat %>%
pull(relig) %>%
fct_lump(prop = -0.01, other_level = "les_autres") %>%
levels()
[1] "No answer" "Don't know" "Inter-nondenominational"
[4] "Native american" "Orthodox-christian" "Moslem/islam"
[7] "Other eastern" "Hinduism" "Buddhism"
[10] "Not applicable" "les_autres"
fct_other
Vous avez envie de remplacer à la mano certaines modalités ? Go fct_other ! Cette fonction vous permet soit de garder une liste de niveaux, soit de droper. Les autres deviennent "other".
gss_cat %>%
pull(marital) %>%
fct_other(keep = "Married") %>%
levels()
[1] "Married" "Other"
gss_cat %>%
pull(marital) %>%
fct_other(drop = c("No answer","Never married")) %>%
levels()
[1] "Separated" "Divorced" "Widowed" "Married" "Other"
fct_recode
Aller, changer le niveau des facteurs à la main, ça vous branche ?
gss_cat %>%
pull(marital) %>%
fct_recode(mar = "Married", sep = "Separated", wid = "Widowed", no_a = "No answer", nev = "Never married", div = "Divorced") %>%
levels()
[1] "no_a" "nev" "sep" "div" "wid" "mar"
fct_relabel
Pour modifier le nom des niveaux de manière globale, fct_relabel est là pour vous : en spécifiant une fonction qui agit sur une chaîne de caractères, tous vos labels sont affectés d'un coup ! Par exemple, mettons les noms en minuscule, et transformons les espaces en "_" :
gss_cat %>%
pull(marital) %>%
fct_relabel(fun = tolower) %>%
fct_relabel(fun = stringr::str_replace_all, " ", "_") %>%
levels()
[1] "no_answer" "never_married" "separated" "divorced" "widowed"
[6] "married"
fct_relevel
Pour trier les facteurs à la main, plutôt que par ordre ou fréquence, comme nous avons vu plus haut. Si vous connaissez la version de {stats} (relevel), il s'agit là d'une généralisation, utilisable avec plus d'un facteur.
gss_cat %>%
pull(marital) %>%
fct_relevel(c("Never married", "Married", "Separated", "Divorced", "Widowed", "No answer")) %>%
levels()
[1] "Never married" "Married" "Separated" "Divorced" "Widowed"
[6] "No answer"
fct_reorder et fct_reorder2
Houla, pourquoi deux fonctions pour réordonner des niveaux ? La première est utilisée lors d'une représentation graphique en 1 dimension, la seconde en 2D (eh oui, tout simplement). Imaginons que nous souhaitions visualiser le nombre moyen d'heures devant la télévision par statuts maritaux :
library(ggplot2)
gss_tv_hours <- gss_cat %>%
group_by(marital) %>%
summarise(age = mean(age, na.rm = TRUE),
tvhours = round(mean(tvhours, na.rm = TRUE), 1))
gss_tv_hours %>%
ggplot(aes(tvhours, marital)) +
geom_point()
 Eh oui, ici y est ordonné en fonction du facteur marital. Ce que l'on veut, c'est qu'il soit ordonné par
Eh oui, ici y est ordonné en fonction du facteur marital. Ce que l'on veut, c'est qu'il soit ordonné par tvhours.
gss_tv_hours %>%
ggplot(aes(tvhours, fct_reorder(marital, tvhours))) +
geom_point()
fct_reorder_2, vous sera utile lorsque vous avez besoin de mapper des couleurs sur une ligne : la légende se trouvera alignée à "l'arrivée" de vos lignes, sur la droite. Comment ça marche ? Les facteurs sont réordonnés avec la valeur y associée à la valeur la plus forte de x.
age_relig <- gss_cat %>%
filter(!is.na(age)) %>%
group_by(age, relig) %>%
count() %>%
ungroup() %>%
mutate(prop = n / sum(n))
ggplot(age_relig, aes(age, prop, colour = relig)) +
geom_line()
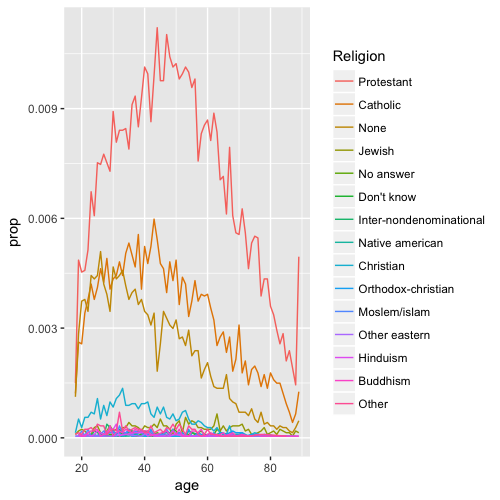
 Le problème ici ? Oui, la légende n'est pas dans le même ordre que les lignes... Eh bien, accueillez à bras ouverts
Le problème ici ? Oui, la légende n'est pas dans le même ordre que les lignes... Eh bien, accueillez à bras ouverts fct_reorder2 !
ggplot(age_relig, aes(age, prop, colour = fct_reorder2(relig, age, prop))) +
geom_line() +
labs(colour = "Religion")
 fct_rev
fct_rev
Inverse l'ordre des facteurs... tout est dans le nom 😉
fct_shift
Décale les facteurs de n crans vers la gauche (et les premiers vont à la fin), ou vers la droite si n est négatif. Une fonction qui peut être utile sur des données cycliques, par exemple avec des dates ! Alors, si vous n'aimez pas la façon dont R ordonne les jours de la semaine :
library(lubridate)
w <- seq(from = ymd("2017-01-01"),
to = ymd("2017-01-31"),
by = 1) %>%
wday(label = TRUE)
levels(w)
[1] "Sun" "Mon" "Tues" "Wed" "Thurs" "Fri" "Sat"
Eh oui, ici la semaine commence le dimanche... Alors, comment changer ça ? Vous nous avez vus venir : avec fct_shift
fct_shift(w, 1) %>% levels()
[1] "Mon" "Tues" "Wed" "Thurs" "Fri" "Sat" "Sun"
fct_shuffle
Mélange de manière aléatoire les niveaux.
fct_shuffle(w) %>% levels()
[1] "Fri" "Tues" "Sat" "Thurs" "Mon" "Wed" "Sun"
fct_unify
Vous avez une liste de facteurs sous la main ? Pour les appliquer à tous les éléments, utilisez fct_unify :
plop <- list(w, factor(letters[1:5]))
fct_unify(plop)
[[1]]
[1] Sun Mon Tues Wed Thurs Fri Sat Sun Mon Tues Wed Thurs Fri
[14] Sat Sun Mon Tues Wed Thurs Fri Sat Sun Mon Tues Wed Thurs
[27] Fri Sat Sun Mon Tues
Levels: Sun < Mon < Tues < Wed < Thurs < Fri < Sat < a < b < c < d < e
[[2]]
[1] a b c d e
Levels: Sun Mon Tues Wed Thurs Fri Sat a b c d e
fct_unique
Enfin, dernier membre de la famille de fct_*, cette fonction permet de renvoyer... les niveaux uniques d'un facteur. La différence avec base::unique ? fct_unique renvoie les valeurs dans l'ordre de leur niveau, pas dans l'ordre de leur apparition.
unique(gss_cat$marital)
[1] Never married Divorced Widowed Married Separated No answer
Levels: No answer Never married Separated Divorced Widowed Married
fct_unique(gss_cat$marital)
[1] No answer Never married Separated Divorced Widowed Married
Levels: No answer Never married Separated Divorced Widowed Married
lvls_expand, lvls_reorder, lvls_revalue et lvls_union
Ces fonctions sont là pour vous travailler à plus bas niveau : dans la pratique, vous aurez plutôt besoin des fonctions que nous venons de voir plus haut. Mais bon, mettons-les ici quand même !
f <- factor(c("a", "b", "c"))
# Réordonner par position
lvls_reorder(gss_cat$marital, 6:1) %>% levels()
[1] "Married" "Widowed" "Divorced" "Separated" "Never married"
[6] "No answer"
# Réordonner par valeur
lvls_revalue(gss_cat$marital,c("Widowed", "Divorced","Separated","Never married", "No answer" , "Married")) %>% levels()
[1] "Widowed" "Divorced" "Separated" "Never married" "No answer"
[6] "Married"
# Ajouter un nouveau facteur
lvls_expand(gss_cat$marital, c("Widowed", "Divorced","Separated","Never married", "No answer" , "Married", "Another level", "And another one")) %>% levels()
[1] "Widowed" "Divorced" "Separated" "Never married" "No answer"
[6] "Married" "Another level" "And another one"
Et voilà, ce n'était pas de tout repos, mais nous avons parcouru tout {forcats} ! Maintenant, à vous de jouer 😉



[…] plus complet (et avec un vrai meme de chat -à ne pas confondre avec la mémère à chat-), c'est ici, sur le blog de ThinkR, que ça se […]