Depuis 2 ans, ThinkR est sollicité pour enseigner (en anglais) tout le meilleur de R aux 60 étudiant.e.s de première année du MSc Data Science for business, cursus conjoint Polytechnique/HEC .
ThinkR forme des profils professionnels de tous horizons sur des thématiques variées depuis 2015. Mais il nous arrive aussi de donner des cours en formation initiale. Cette année, nous avons enseigné à notre deuxième promotion du MSc Data Science for business. Le module dispensé par une partie de l’équipe, intitulé “R for Data Science”, couvre 8 jours alternant théorie et pratiques de fin septembre à mi-décembre.
Nous l’avons résolument orienté vers la mise en oeuvre de R comme usine logicielle. Certes, on y aborde la manipulation de données, la datavisualisation avec ses “do’s and don’t”, la mise en œuvre de quelques tests et modèles statistiques ou encore – c’est une nouveauté cette année – la manipulation de données géographiques et la création de cartes, et, enfin la communication des résultats avec Shiny. Mais on trouve aussi (surtout ?) dans ce programme tout ce qui nous semble indispensable au passage à l’échelle et la mise en production de code R propre, lisible, maintenable…
C’est à dire que nous avons insisté sur l’approche “.Rmd first”, la mise en fonction “dès le premier copier-coller”, la programmation dans le {tidyeval}, la programmation fonctionnelle avec {purrr}, la mise en package pour la documentation des fonctions et l’exécution de tests unitaires, la mise en modules des briques fonctionnelles Shiny…dans des projets versionnés. Tout un programme ! Il condense toute notre expertise et savoir-faire.
En sus des devoirs individuels, les étudiant.e.s ont travaillé en groupe de 5 sur une thématique data de leur choix. Notre évaluation portait pour une moitié sur les caractéristiques techniques des produits “usinés” dans leur forge R et la mise en application des principes exposés en cours et pour l’autre moitié sur le storytelling lors de l’exposé.
Voici un résumé des 12 présentations :
Sommaire
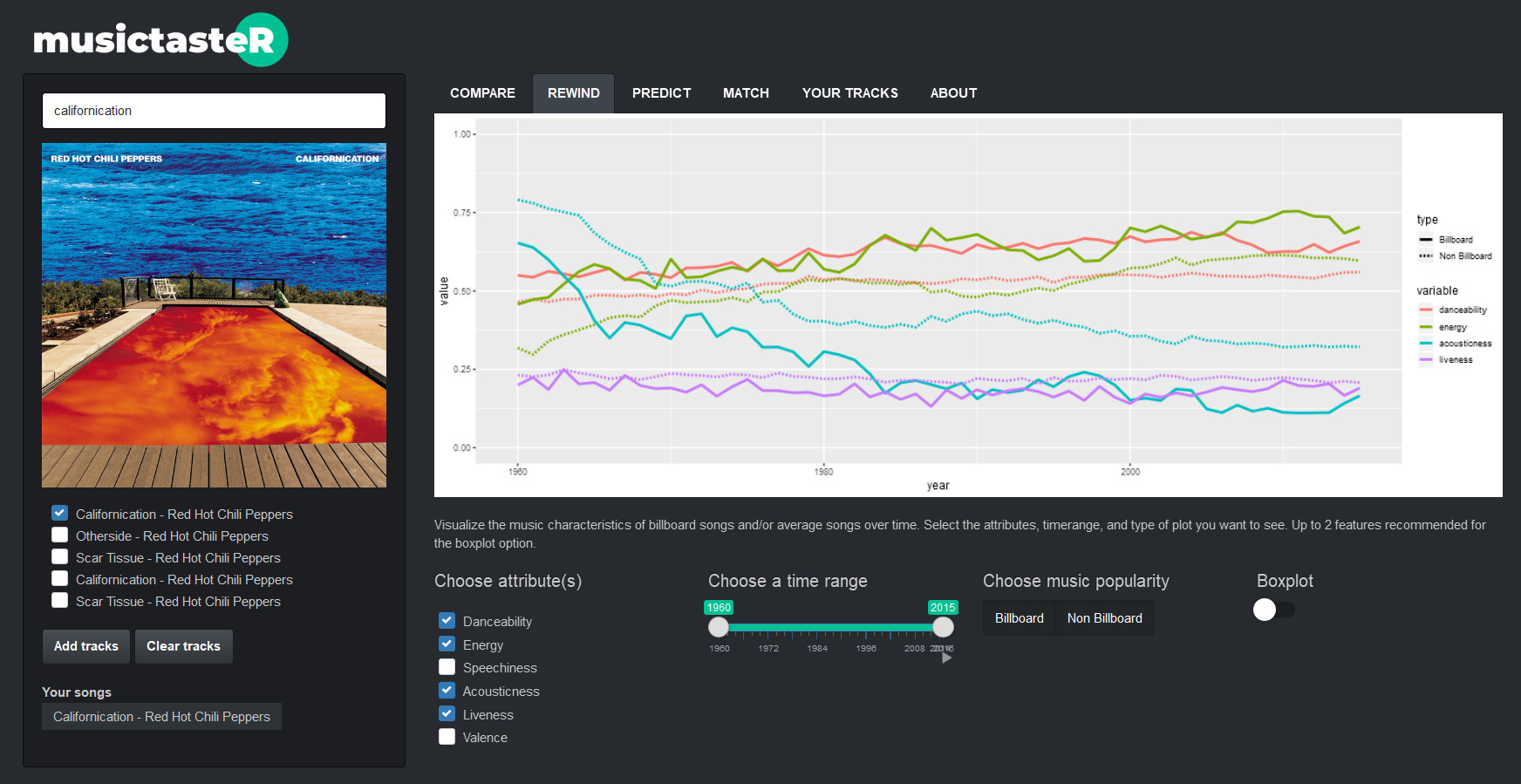
Your dream car
Acheter sa voiture d’occasion, une galère ? L’ambition affichée de ce projet est de vous aider à déterminer les options qui coûtent le plus cher (kilométrage, transmission, revendeur professionnel…) ou qui vous permettront de faire des économies pour un type de véhicule donné. Les compromis ont été modélisés sur la base des véhicules mis en vente et « scrapés » sur le site Paruvendu en octobre et novembre 2018. Une fois le choix du type de véhicule opéré, il est possible d’identifier la localisation des mise en ventes.
https://github.com/ludmilaexbrayat/findyourcar
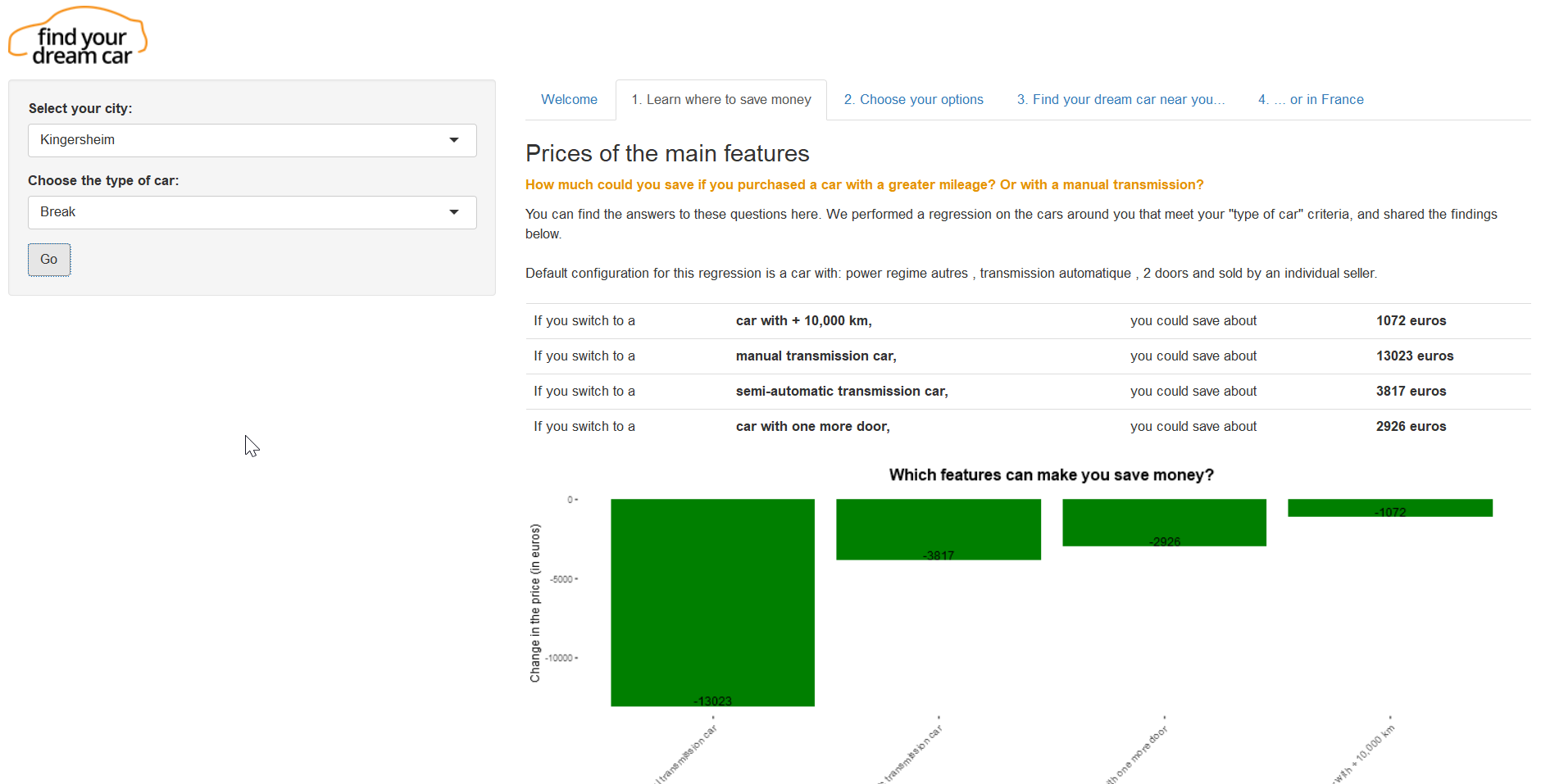
MusictastR
MusictastR est un package qui a exploré 50 000 chansons du top 100 et 150 000 chansons « moyennes » de 1960 à 2015 pour déterminer les caractéristiques des musiques qui font un top ou un flop. L’application web Shiny qui en résulte permet de regarder comment une (ou un lot de) chanson(s) sélectionnée(s) par l’utilisateur se positionne au cours du temps par rapport aux chansons d’une époque donnée
https://github.com/rubasic/rubasic/tree/master/musictasteR
Deputy debates
Dans ce projet a effectif réduit, il s’agissait de faire en sorte que chaque citoyen puisse s’approprier les interventions parlementaires de nos députés en mobilisant l’API de https://www.nosdeputes.fr/. Une analyse de sentiment a été réalisée sur une partie des données via les « cognitives services » de Microsoft Azure : https://azure.microsoft.com/fr-fr/services/cognitive-services/text-analytics/
https://gitlab.com/DanielWin/r-project-depute
Interventions of the FDNY
Ce groupe souhaitait travailler avec les pompiers de Paris. Après avoir auditionné les acteurs concernés sur leurs besoins et leurs difficultés à exploiter les données existantes, un prototype d’application est réalisée sur les données des pompiers new-yorkais.
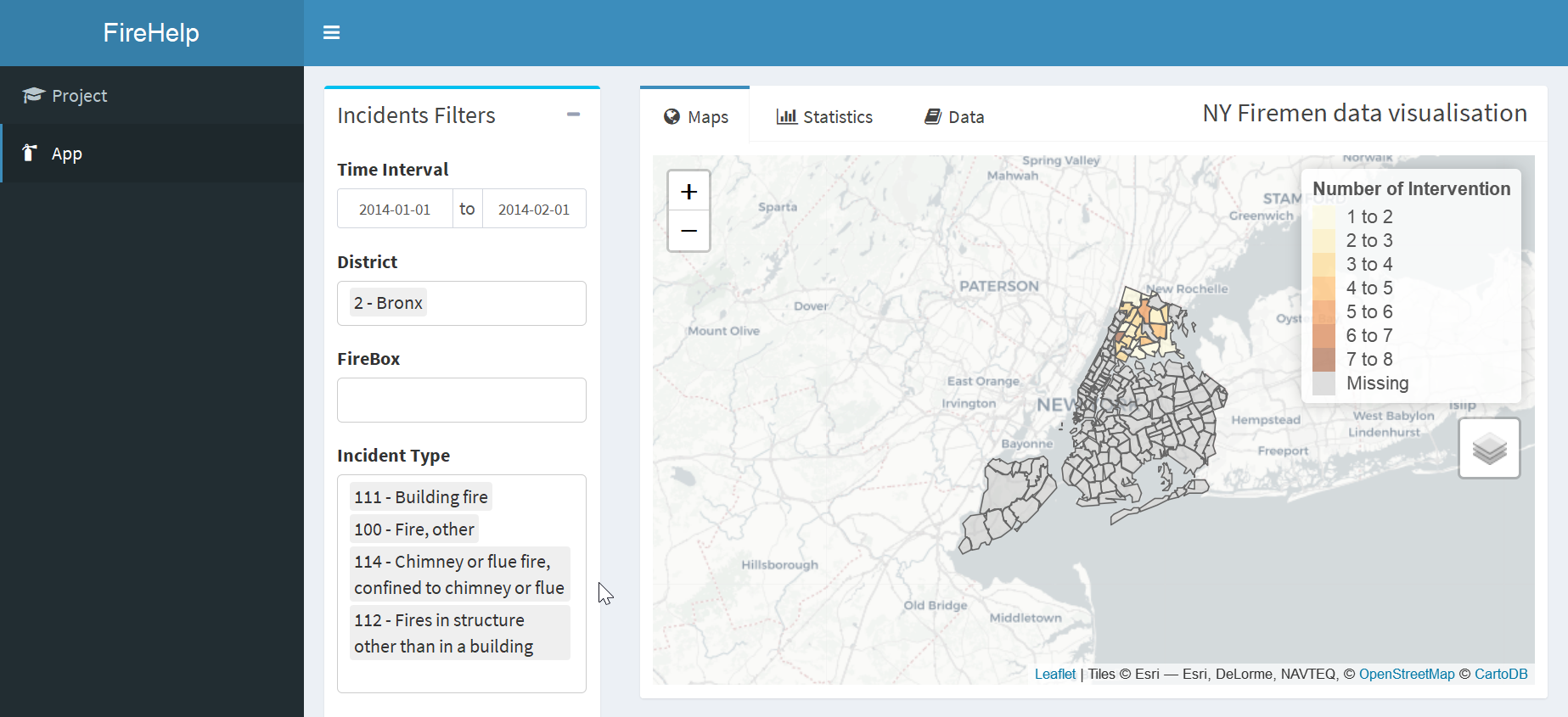
https://github.com/adriensas/XHEC-R-GROUP-PROJECT-FDNY
Trading cryptocurrencies
Ce groupe a élaboré un outil qui permet de comparer des stratégies de « trading » sur différentes plateformes et devises. Les cours sont mis à jour en temps réel et l’application dispose d’un module qui tâche d’évaluer la notoriété des devises via leur fréquence d’apparition dans la presse.
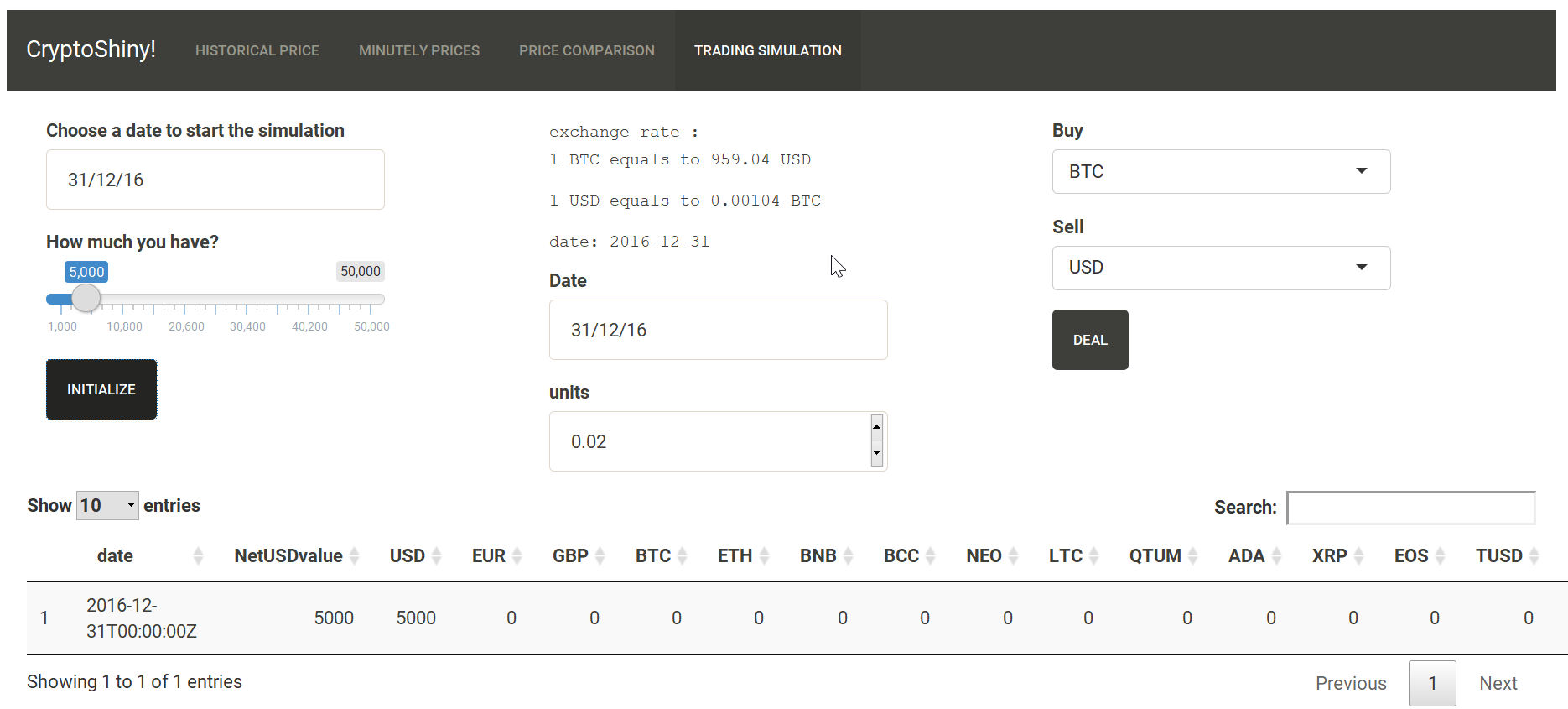
https://github.com/fernandopf/ThinkRProject
Taylor made real estate
Fini les galères (bis) pour chercher un appartement à Paris, ce projet vous aide à trouver le bien qui vous correspond compte-tenu du prix, de la surface, du nombre de chambres bien entendu mais également la proximité des écoles, des magasins, des équipements culturels. Les données de https://www.castorus.com/ ont été « scrapées » et le contenu des annonces analysées pour calculer les localisations probables des biens.
https://github.com/paris-appartemnt-project/apartment_project
New York City Taxi fare
Modéliser le prix de la course en taxi à New York (et en finir avec l’éternel débat Yellow cab ou Uber ?) est le sujet de cette compétition Kaggle : https://www.kaggle.com/c/new-york-city-taxi-fare-prediction. Les étudiants ont proposé un algorithme original pour y répondre en découpant la ville en une grille. Chaque tuile reflète une densité de prix calculée à l’aune des trajets passés en tenant compte de l’heure, du nombre de passagers…
https://github.com/ProjetRTaxeFare/TF
Food facts with FoodX
Facilement corruptibles quand il s’agit de nourriture, nous avons été particulièrement séduit par ce projet puisqu’il a commencé par une distribution de douceurs à base de chouquettes, bonbons et autres cookies. FoodX est une application qui permet de scanner le code barre d’un produit alimentaire et l’ajouter ainsi à une liste d’ingrédients avec lesquels on souhaiterait réaliser une recette. Tirée de marmiton, les recettes sont assorties d’un score nutritionnel.
https://github.com/antoinepay/foodx
Japanese restaurant visitors forecast
Pouvoir prévoir la fréquentation d’un restaurant c’est mieux gérer les approvisionnements, le personnel nécessaire au bon fonctionnement… C’est l’objet de cette compétition Kaggle https://www.kaggle.com/c/recruit-restaurant-visitor-forecasting/data et l’exercice choisi par ce groupe pour appliquer un algo d’extreme gradient boosting.
Win money with your train delays
A ce qu’il paraît, les trains de la SNCF sont toujours en retard. On prends les paris ? En imaginant une plateforme imaginaire de paris en ligne sur les retards de train, ce groupe a mis en scène les données SNCF des régularités mensuelles par liaisons https://ressources.data.sncf.com/explore/dataset/regularite-mensuelle-tgv-aqst/table/?sort=periode

https://github.com/ZiggerZZ/Rproject
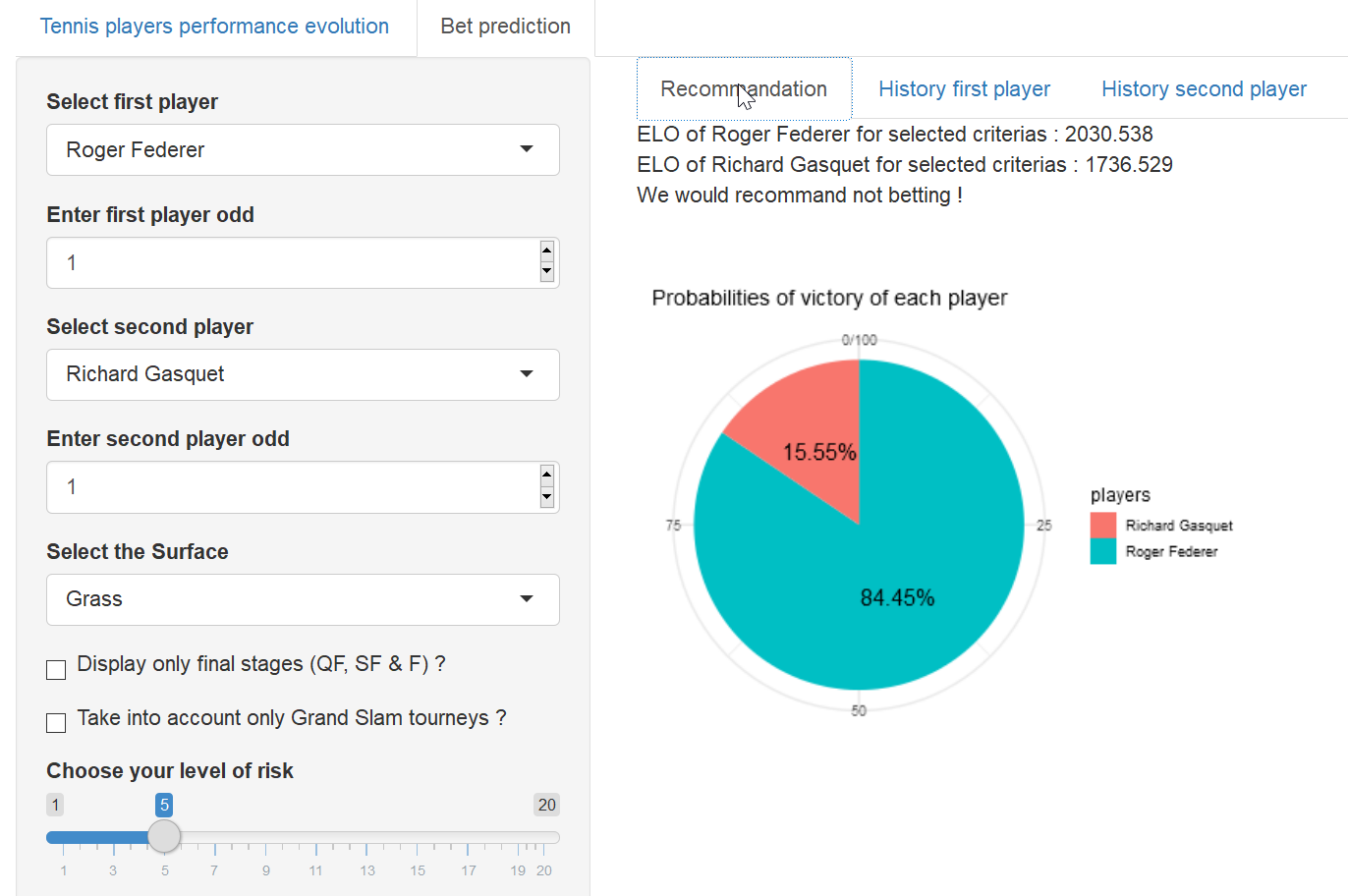
Tennis matches
Parier sur des matches de tennis ? A priori, non merci. A tort ! Voici une des meilleures façon de gagner de l’argent en 2019 et on espère que vous direz que vous l’avez vu chez ThinkR en premier. En partant d’un jeu de données qui récapitule les joueurs impliqués dans les matches ATP depuis 1968, les étudiants ont calculé le score elo https://fr.wikipedia.org/wiki/Classement_Elo des joueurs afin de calculer l’issue probable de n’importe quel match de tennis.
Je mets un CAMEMBERT, oui mesdames, messieurs et non binaires, un CAMEMBERT en illustration de ce projet alors que j’ai écrit noir sur blanc dans le cours qu’ il était interdit de tracer ce genre de graphique…
C’est dire si je vous encourage à parier sur le tennis…
EQUIP’MAP
Ce projet s’est intéressé à la base de données des équipements de l’INSEE afin d’en proposer un outil de monitoring de la dépense publique en y aggrégeant des données sur la criminalité et le taux de pauvreté.
https://github.com/victoiredechab/EquipmapPackage
Merci à tous les étudiant.e.s pour leur travail et leur prestation ce jour là. En espérant vous avoir transmis l’outillage nécessaire à façonner des produits de data science de qualité avec R… Bonne continuation !


