
Eh oui, 2017 est déjà (presque) fini… À l’heure qu’il est, on boucle les derniers dossiers de l’année, et on se prépare psychologiquement à aller célébrer la nouvelle année comme il se doit. Bref, « pas le temps de niaiser » comme le disent si bien nos amis d’outre-Atlantique.
Histoire de se changer les idées avant de décoller, nous vous avons concocté un deuxième volet de R de jeu, avec la thématique fin d’année !
Sommaire
All I want for Christmas is data
Se connecter à Spotify, on l’a déjà fait, on ne va pas vous en reparler 😉
library(httr)
app_id <- "app_spotify"
client_id <- "***"
client_secret <- "***"
spoti_ep <- httr::oauth_endpoint(
authorize = "https://accounts.spotify.com/authorize",
access = "https://accounts.spotify.com/api/token")
spoti_app <- httr::oauth_app(app_id, client_id, client_secret)
access_token <- httr::oauth2.0_token(spoti_ep, spoti_app, scope = "user-read-private")
Hop, une bonne chose de faite. On va se faire une petite recherche avec la thématique New Year, vous en pensez quoi ?
tracks <- GET("https://api.spotify.com/v1/search?q=new%20year&type=track",
config(token = access_token), query = list(limit = 50))
content(tracks)$tracks$total
[1] 35890
Est-ce que Spotify va nous laisser aller chercher tout ça ? On a le droit d'y aller 50 par 50... lançons le test 🙂
library(tidyverse)
library(jsonlite)
get_tracks <- function(offset){
print(offset)
api_res <- GET("https://api.spotify.com/v1/search?q=new%20year&type=track",
config(token = access_token), query = list(limit = 50, offset = offset))
played <- api_res$content %>% rawToChar() %>% fromJSON(flatten = TRUE)
return(as_tibble(played$tracks$items))
}
safe_tracks <- safely(get_tracks)
new_year_songs <- map(seq(0, 35890, 50), safe_tracks)
clean_songs <- new_year_songs %>% map("result") %>% compact() %>% bind_rows()
dim(clean_songs)
[1] 35890 25
Il semblerait qu'on ait réussi à toutes les avoir !
clean_songs <- select(clean_songs, artists, duration_ms, explicit,
name, popularity, type, album.name)
Visualisation
Il nous faudrait une petite palette de couleurs spécialement prévue pour le Nouvel An, non ? Aller, on va emprunter celles de Color-Hex.
library(rvest)
library(glue)
get_palettes_list <- function(search){
search <- URLencode(search)
read_html(glue("http://www.color-hex.com/color-palettes/?keyword={search}")) %>%
html_nodes(".palettecontainerlist a") %>%
html_attr("href") %>%
stringr::str_extract_all("([0-9]+)") %>%
as_vector()
}
list_palettes <- get_palettes_list("new year")
get_palette <- function(page){
Sys.sleep(0.5)
read_html(glue("http://www.color-hex.com/color-palette/{page}")) %>%
html_table() %>%
modify_depth(1, "Hex") %>%
as_vector()
}
full_palette <- map(list_palettes, get_palette) %>% as_vector() %>%
unique() %>% discard( ~ .x == "ffffff")
full_palette
[1] "#000934" "#1624a1" "#a2bdf2" "#fc5b8d" "#a8026e"
[6] "#f90000" "#9a1010" "#f4eb1a" "#e1d921" "#e79516"
[11] "#000000" "#cfcfcf" "#14054c" "#fffff0" "#ffd376"
[16] "#ffe700" "#c900ff" "#2f00ff" "#ff00c1" "#7cff00"
On a de quoi faire...
Maintenant, allons regarder rapidement ce qu'il se trame dans ce dataset ? Des tracks plutôt populaires ?
library(ggthemes)
ggplot(clean_songs) +
aes(x = popularity) +
geom_density(fill = sample(palette, 1)) +
labs(title = "Popularité des tracks du nouvel an",
subtitle = "données via Spotify",
x = "Popularité",
y = "Densité",
caption = "thinkr.fr") +
theme_few()
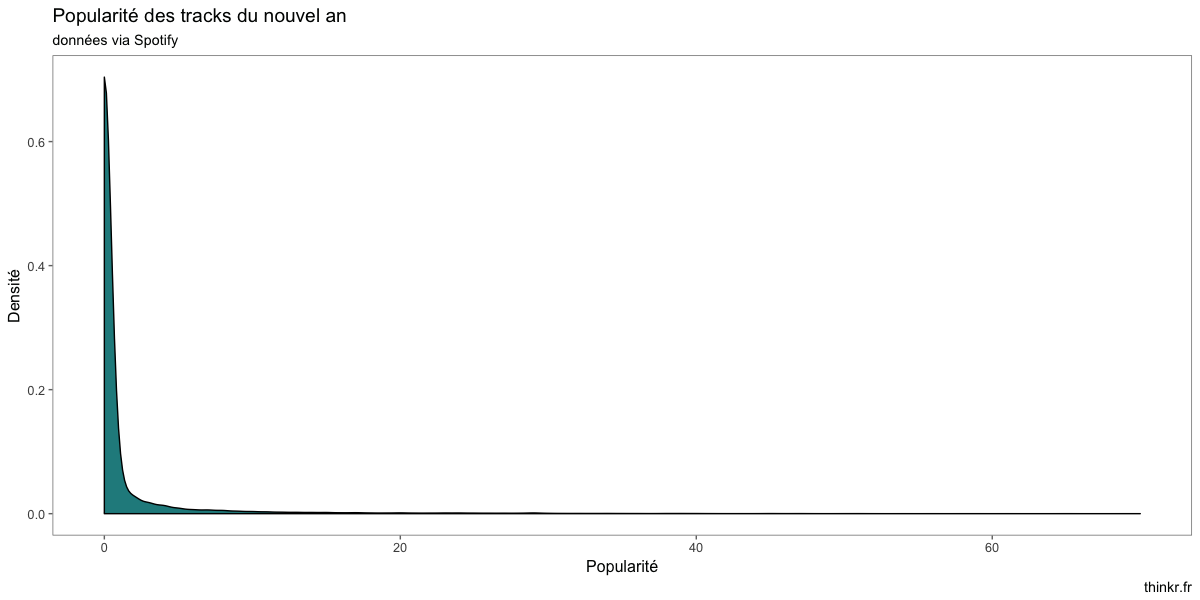
À première vue, quelques morceaux populaires, et un paquet de morceaux moins populaires. Lesquels sont en top de liste ?
clean_songs %>%
select(name, popularity) %>%
top_n(10) %>%
knitr::kable()
| name | popularity |
|---|---|
| New Year’s Day | 70 |
| Happy New Year | 56 |
| Happy New Year | 65 |
| Please Come Home For Christmas | 69 |
| My Dear Acquaintance [A Happy New Year] - iTunes Live Session Performance | 52 |
| What Are You Doing New Year's Eve? | 58 |
| All I Want for Christmas Is New Year's Day | 61 |
| All I Want for Christmas Is New Year's Day | 65 |
| What Are You Doing New Year's Eve? | 59 |
| New Year's Day | 54 |
Et les artistes les plus présents dans notre jeu de données ?
clean_songs %>%
count(artists, sort = TRUE) %>%
top_n(10) %>%
ggplot() +
aes(reorder(artists, n), n) +
geom_col(fill = sample(full_palette, 1)) +
coord_flip() +
labs(title = "Artistes et tracks du nouvel an",
subtitle = "données via Spotify",
x = "Artistes",
y = "Nombre de morceaux",
caption = "thinkr.fr") +
theme_few()
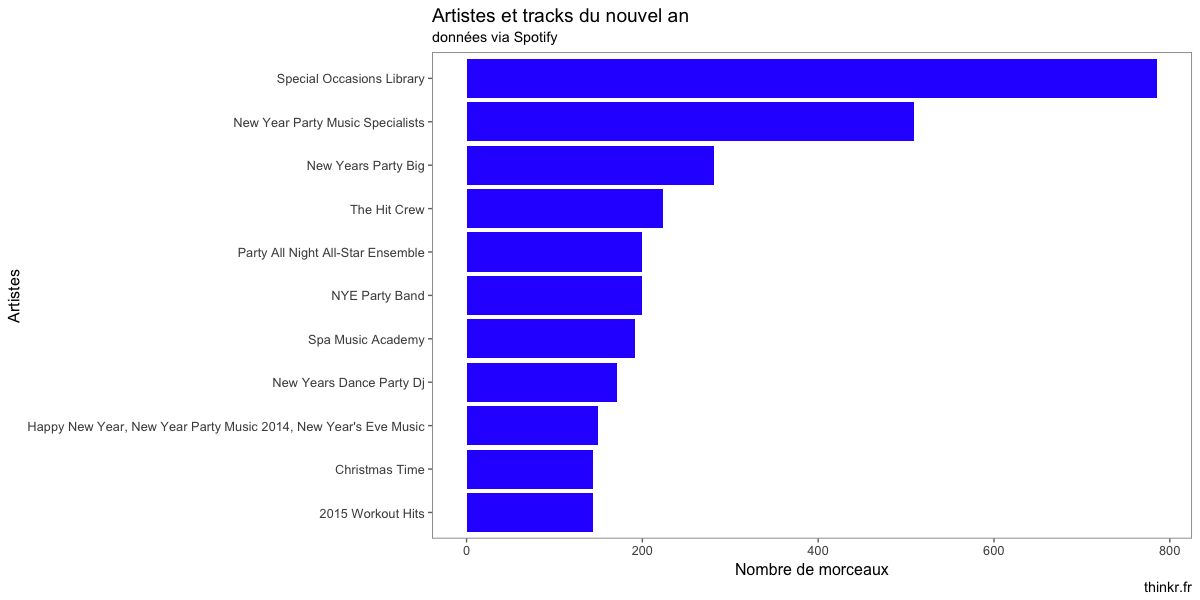 Maintenant, on se ferait bien une fonction de recommandation de playlist, non ? Disons, une fonction qui permet de créer une playlist adaptée au temps qu'on veut y passer. Commençons par une fonction qui va sampler jusqu'à atteindre un certain niveau :
Maintenant, on se ferait bien une fonction de recommandation de playlist, non ? Disons, une fonction qui permet de créer une playlist adaptée au temps qu'on veut y passer. Commençons par une fonction qui va sampler jusqu'à atteindre un certain niveau :
sample_until<- function(tbl, col, threshold){
col <- enquo(col)
vec <- pull(tbl, !! col)
if ( min(vec) > threshold ) stop("Impossible de trouver une combinaison pour ce threshold")
res <- sample_n(tbl, 1)
while( sum( pull(res, !! col) ) < threshold) {
res <- bind_rows(res, sample_n(tbl, 1)) %>% distinct()
}
res
}
sample_until(iris, Sepal.Length, 30) %>% knitr::kable()
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 6.4 | 3.2 | 5.3 | 2.3 | virginica |
| 4.9 | 3.1 | 1.5 | 0.2 | setosa |
| 4.8 | 3.4 | 1.9 | 0.2 | setosa |
| 5.8 | 2.7 | 5.1 | 1.9 | virginica |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5.4 | 3.0 | 4.5 | 1.5 | versicolor |
Et voilà ! Combinons maintenant ça avec notre jeu de données de chansons :
clean_songs$artists <- modify_depth(clean_songs$artists, 1, ~ .x$name) %>%
modify_depth(1, ~ paste(.x, collapse = ', ')) %>%
as_vector()
make_me_a_playlist <- function(duree_s, popularite_max, explicit_filter = FALSE){
duree_milli <- duree_s * 1000
good <- clean_songs %>%
filter(popularity <= popularite_max)
if(explicit_filter) good <- filter(good, ! explicit)
sample_until(good, duration_ms, duree_milli) %>%
select(artists, name, duration_ms) %>% knitr::kable()
}
make_me_a_playlist(600, 50)
| artists | name | duration_ms |
|---|---|---|
| Dj Luca Projet | Down with the Trumpets | 188186 |
| Sofi Maeda | Merry Christmas & Happy New Year | 77468 |
| DJ Lucas | Survival - The Champions Olympionic Music - Karaoke Version Originally Performed By Muse | 320261 |
| Saturday Mix Dj. | Royals | 190918 |
\o/
À la recherche de la soirée parfaite
C'est bien beau d'avoir une belle playlist, mais il serait mieux de trouver un endroit pour jouer ces morceaux. Qu'est-ce que nous propose Facebook ?
get_event <- function(fb_url){
res <- GET(fb_url)
res <- content(res)
return(list(id = map(res$data, "id"), paging = res$paging))
}
# La première page :
# Le token est temporaire, ça ne marchera pas chez vous ;)
res <- get_event("https://graph.facebook.com/v2.11/search?q=new%20year&type=event&access_token=EAACEdEose0cBAEwhntvjdDENCoU19y3He5q7L6cHoyL9J3RkpxuZCHGxXxN2UZCfFO5d7Ng90MnMh8lbnSP8cZA71iked9ZBLr6wrredSmGCZCY7BgwIXUGEEd0PRdyuD8lhymPdEJjB413T6fqGra0rQ4Wzb3l23auncQDE2xl5cVpgqyIiBAcazYzbFVo8ZD")
next_page <- try(res$paging$`next`)
id_list <- res$id
while( length(next_page) != 0 ) {
res <- get_event(next_page)
next_page <- try(res$paging$`next`)
id_list <- c(id_list, res$id)
}
76 événements, c'est plutôt pas mal. On va scraper tout ça !
event_details <- function(id){
fromJSON(glue("https://graph.facebook.com/v2.11/{id}?access_token=EAACEdEose0cBAEwhntvjdDENCoU19y3He5q7L6cHoyL9J3RkpxuZCHGxXxN2UZCfFO5d7Ng90MnMh8lbnSP8cZA71iked9ZBLr6wrredSmGCZCY7BgwIXUGEEd0PRdyuD8lhymPdEJjB413T6fqGra0rQ4Wzb3l23auncQDE2xl5cVpgqyIiBAcazYzbFVo8ZD"))
}
all_events <- map(id_list, event_details)
Comme souvent lorsque l'on appelle des API, nous avons une liste irrégulière (en JSON, non-tabulaire), que nous avons besoin de transformer en tableau. Go pour une fonction qui réglera ça !
library(lubridate)
tibble_that <- function(list){
tibble(desc = list$description %||% NA,
start_time = ymd_hms(list$start_time) %||% NA,
end_time = ymd_hms(list$end_time) %||% NA,
name = list$name %||% NA,
place = list$place$name %||% NA,
city = list$place$location$city %||% NA,
country = list$place$location$country %||% NA,
street = list$place$location$street %||% NA,
zip = list$place$location$zip %||% NA,
placeid = list$place$id %||% NA
)
}
events <- map_df(all_events, tibble_that)
Alors, quels pays peut-on viser ?
library(lubridate)
tibble_that <- function(list){
tibble(desc = list$description %||% NA,
start_time = ymd_hms(list$start_time) %||% NA,
end_time = ymd_hms(list$end_time) %||% NA,
name = list$name %||% NA,
place = list$place$name %||% NA,
city = list$place$location$city %||% NA,
country = list$place$location$country %||% NA,
street = list$place$location$street %||% NA,
zip = list$place$location$zip %||% NA,
placeid = list$place$id %||% NA
)
}
events <- map_df(all_events, tibble_that)
events %>%
count(city) %>%
na.omit() %>%
top_n(5) %>%
arrange(desc(n)) %>%
ggplot() +
aes(reorder(city, n), n) +
geom_col(fill = sample(full_palette, 1)) +
coord_flip() +
labs(title = "Villes avec des événements 'New Year'",
subtitle = "données via Facebook",
x = "Ville",
y = "Nombre d'événements",
caption = "thinkr.fr") +
theme_few()
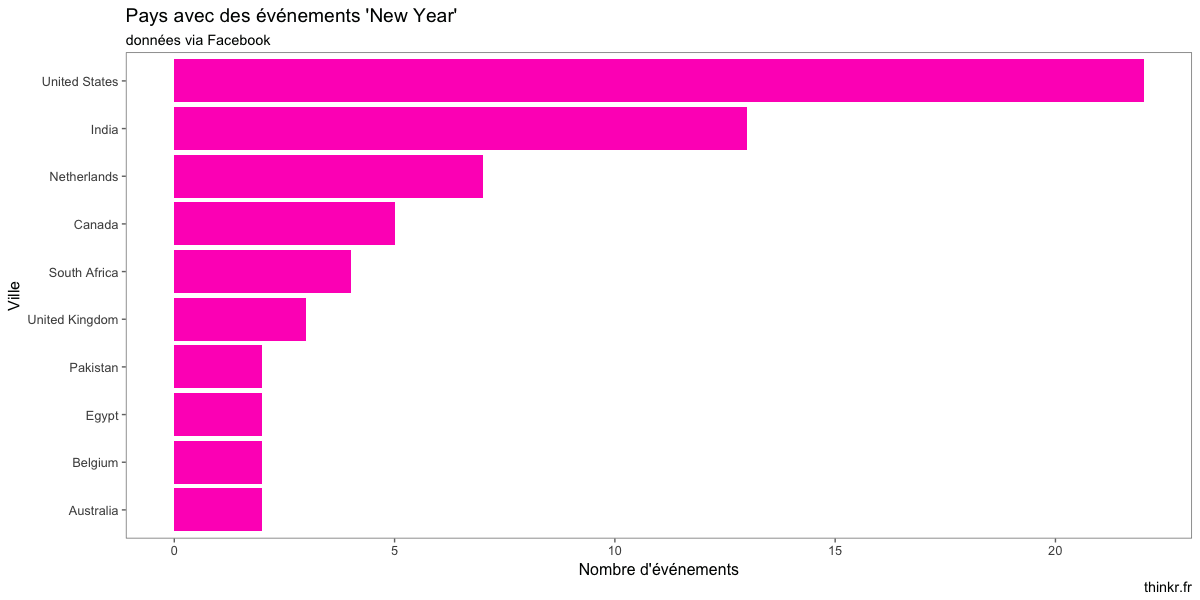
Il va falloir qu'on voit ce qu'on a de plus proche. Petit tour du côté de l'API distance24 ?
get_route <- function(from, to){
if (is.na(to)) {
return(NULL)
}
from_clean <- URLencode(from)
to_clean <- URLencode(to)
a <- GET(glue("http://fr.distance24.org/route.json?stops={from_clean}|{to_clean}"))
tibble(from = from,
to = to,
dist = content(a)$distances[[1]])
}
travel <- map_df(events$city, ~ get_route("Rennes", .x))
Rendez-vous au plus proche :
travel %>%
top_n(- 5) %>%
arrange(dist) %>%
knitr::kable()
| from | to | dist |
|---|---|---|
| Rennes | London | 394 |
| Rennes | London | 394 |
| Rennes | Gent | 509 |
| Rennes | Brussels | 532 |
| Rennes | Liverpool | 597 |
Direction Londres alors 😉
Les douze développeurs de minuit
Enfin, on a prévu de bouger... mais il se passe peut-être trop de choses sur GitHub ? Alerte #FOMO
github_app <- oauth_app("github", "***", "***")
access_token <- oauth2.0_token(oauth_endpoints("github"), github_app)
res <- GET(url = "https://api.github.com/search/repositories?q=new+year&sort=stars&order=desc", config(token = access_token))
content(res)$total_count
[1] 1527
get_search <- function(page, search){
Sys.sleep(2)
search <- URLencode(search)
res <- GET(url = glue("https://api.github.com/search/repositories?q={search}&per_page=100&page={page}"),
config(token = access_token))
# Surveillons le rate limit
message(res$headers$`x-ratelimit-remaining`)
res$content %>% rawToChar() %>% fromJSON() %>% .$items %>% discard(is.data.frame)
}
all_github_ny <- map_df(.x = 1:15, .f = ~ get_search(.x, "New Year"))
dim(all_github_ny)
[1] 1000 70
Ah, c'est étrange, 1500 résultats et des bananes, et nous n'avons que les 1000 premiers résultats... On ne peut pas avoir la page 15 ?
GET(url = glue("https://api.github.com/search/repositories?q=New%20year&per_page=100&page=15"),
config(token = access_token))
Response [https://api.github.com/search/repositories?q=New%20year&per_page=100&page=15]
Date: 2017-12-27 16:35
Status: 422
Content-Type: application/json; charset=utf-8
Size: 134 B
{
"message": "Only the first 1000 search results are available",
"documentation_url": "https://developer.github.com/v3/search/"
}
Ceci explique cela ! Seulement les 1000 premiers résultats sont renvoyés par l'API de Github !
Regardons un peu ce qu'il se trame dans ce jeu de données.
all_github_ny %>%
count(language) %>%
na.omit() %>%
top_n(10) %>%
arrange(desc(n)) %>%
ggplot() +
aes(reorder(language, n), n) +
geom_col(fill = sample(full_palette, 1)) +
coord_flip() +
labs(title = "Langages sur Github pour 'New Year'",
subtitle = "données via GitHub",
x = "Langages",
y = "Nombre de repos",
caption = "thinkr.fr") +
theme_few()
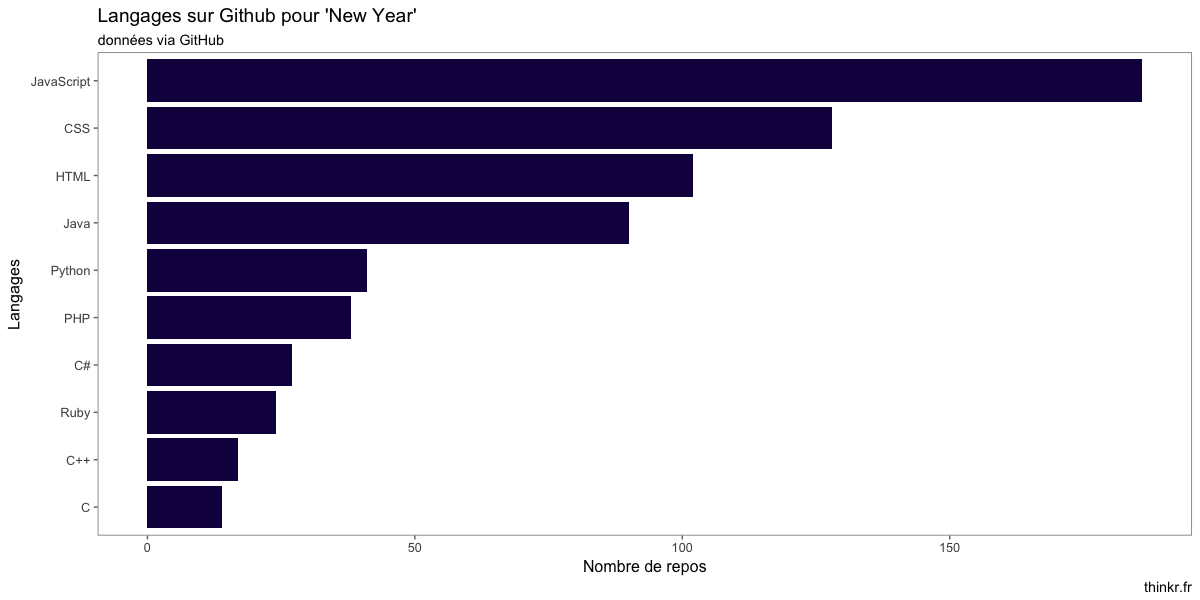 Pas beaucoup de R, donc... et plutôt des langages orientés web...
Pas beaucoup de R, donc... et plutôt des langages orientés web...
all_github_ny %>%
filter(language == "R") %>%
nrow()
[1] 5
Alors, de quoi ça parle tout ça ?
library(tidytext)
all_github_ny %>%
unnest_tokens(word, description) %>%
anti_join(stop_words) %>%
count(word) %>%
na.omit() %>%
top_n(10) %>%
knitr::kable()
| word | n |
|---|---|
| 2016 | 32 |
| 2017 | 33 |
| app | 39 |
| countdown | 34 |
| final | 35 |
| game | 22 |
| happy | 91 |
| project | 77 |
| year's | 42 |
| 新年 | 23 |
| 的 | 22 |
Au final, pas mal d'application web en JavaScript, HTML et CSS pour le final countdown...
Allez, c'est pas tout, mais on a un Nouvel An à développer nous 😉


