
Bon, avouons-le, sur ce blog, ça ne rigole pas. Entre tutos sur le machine learning, le text-mining et des détails sur {forcats}, on ne prend plus trop le temps de s’amuser avec R. Et des fois, ça fait du bien de retrouver le bac à sable 😉
Alors, aujourd’hui, pas de théorie, que de la pratique, avec une session API, dataviz, et statistiques !
Sommaire
Hello Spotify
Les données Spotify, c’est sûr, il y a un package pour ça. Mais bon, où serait le fun si nous ne faisions pas les choses à la main ?
# Enfin... presque tout à la main
library(httr)
Web scraping
Première étape, qui ne se fait pas dans R, créer une application sur la plateforme développeur de Spotify. Ça, malheureusement, nous n’allions pas y échapper. Maintenant, il va falloir faire venir notre token dans notre session R.
# Donnons un joli petit nom à notre application
app_id <- "app_spotify"
# Les tokens de l'app
client_id <- "***"
client_secret <- "****"
# Créons un oauth_endpoint, autrement dit un identifiant pour accéder à l'API
spoti_ep <- httr::oauth_endpoint(
authorize = "https://accounts.spotify.com/authorize",
access = "https://accounts.spotify.com/api/token")
spoti_app <- httr::oauth_app(app_id, client_id, client_secret)
access_token <- httr::oauth2.0_token(spoti_ep, spoti_app, scope = "user-library-read user-read-recently-played")
---
authorize: https://accounts.spotify.com/authorize
access: https://accounts.spotify.com/api/token
app_spotify
key: ***
secret:
access_token, token_type, expires_in, refresh_token, scope
---
Eh voilà, {httr} a fait une grande partie du boulot à notre place. Il vient notamment d‘enregistrer dans notre dossier local un fichier .httr-oauth, qui contient le token pour effectuer des requêtes sur l’API. Allons chercher les données de ma bibliothèque.
tracks <- GET("https://api.spotify.com/v1/me/tracks", config(token = access_token), query = list(limit = 50))
content(tracks)$total
[1] 2367
Donc, 2367 tracks à aller chercher. Malheureusement, Spotify ne permet de requêter que par groupe de 50 maximum. Et avouons-le, on ne va pas y aller à la main, 50 par 50... Un petit map ?
library(tidyverse)
library(jsonlite)
get_tracks <- function(offset){
print(offset)
api_res <- GET("https://api.spotify.com/v1/me/tracks", config(token = access_token), query = list(limit = 50, offset = offset))
played <- api_res$content %>%
rawToChar() %>%
fromJSON(flatten = TRUE)
tibble(track = played$items$track.name %||% NA,
trackid = played$items$track.album.id %||% NA,
track_uri = gsub("spotify:track:", "", played$items$track.uri) %||% NA,
album_name = played$items$track.album.name %||% NA,
album_id = played$items$track.album.id %||% NA,
artist = map_chr(played$items$track.artists, ~.x$name[1] %||% NA),
duration = played$items$track.duration_ms %||% NA,
explicit = played$items$track.explicit %||% NA,
popularity = played$items$track.popularity %||% NA)
}
colin_tracks <- map_df(seq(0,2367, 50), get_tracks)
dim(colin_tracks)
[1] 2367 9
2367 individus, répartis sur 9 variables.
Dataviz
Aller, on regarde un peu ce qu'il s'y trame, dans ce dataset ? Des tracks plutôt populaires ?
library(viridisLite)
library(ggthemes)
palette <- viridis(256, option = "D")
ggplot(colin_tracks, aes(x = pop)) +
geom_density(fill = palette[1]) +
labs(title = "Popularité des tracks de la bibliothèque",
subtitle = "données via Spotify",
x = "Popularité",
y = "Densité",
caption = "thinkr.fr") +
theme_few()
 Pas très populaires, les morceaux de cette bibliothèque, à première vue...
Pas très populaires, les morceaux de cette bibliothèque, à première vue...
Côté durée, un rapide coup d'oeil nous donne l'impression que c'est assez varié... juste une impression ?
colin_tracks %>%
# Transformons les durées en secondes
mutate(duration = duration / 1000) %>%
ggplot(aes(x = duration)) +
geom_density(fill = sample(palette, 1)) +
labs(title = "Durée des tracks de la bibliothèque",
subtitle = "données via Spotify",
x = "Durée du morceau",
y = "Densité",
caption = "thinkr.fr") +
theme_few()
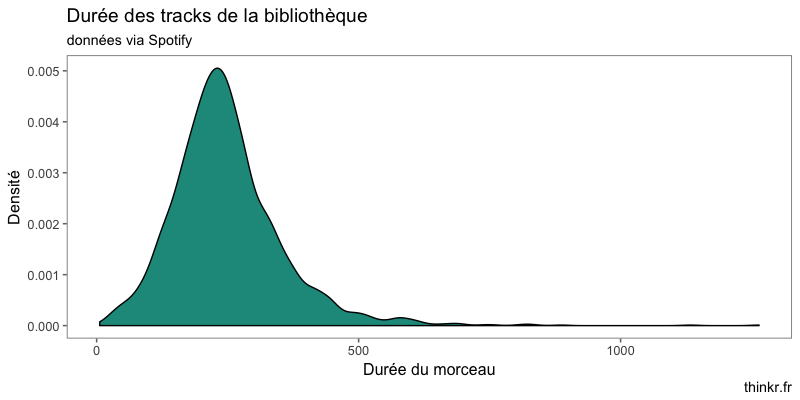 Une distribution avec un mode autour de 250 secondes (environ 4 minutes).
Une distribution avec un mode autour de 250 secondes (environ 4 minutes).
Bon, ils sont sortis quand tous ces albums ? Nous allons avoir besoin de faire une nouvelle requête :
library(glue)
get_album <- function(id){
# Évitons de se faire kicker par l'API Spotify
Sys.sleep(0.1)
call <- GET(glue("https://api.spotify.com/v1/albums/{id}"), config(token = access_token), query = list(limit = 50)) %>% content()
tibble(artist = call$artists[[1]]$name %||% NA,
album = call$name %||% NA,
album_cover = call$images[[1]]$url %||% NA,
release = gsub("(^....).*","\\1", call$release_date) %||% NA,
tracks = length(call$tracks$items) %||% NA,
genre = ifelse(length(call$genres) == 0, NA, call$genres),
popularity = call$popularity %||% NA)
}
colin_albums <- map_df(unique(colin_tracks$album_id), get_album)
Donc, niveau année de sortie, on en est où ?
ggplot(colin_albums, aes(as.numeric(release))) +
geom_density(fill = sample(palette, 1)) +
labs(title = "Année de sortie des albums de la bibliothèque",
subtitle = "données via Spotify",
x = "Année de sortie de l'album",
y = "Densité",
caption = "thinkr.fr") +
theme_few()
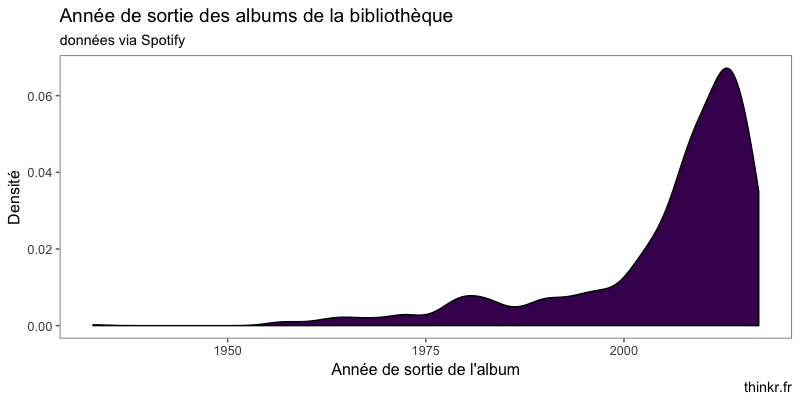 Globalement, les morceaux sont assez récents.
Globalement, les morceaux sont assez récents.
Track by track
Et si on se faisait une petite analyse des tracks ? Merci Spotify de nous fournir des données sur les caractéristiques audio de chaque morceau 🙂
track_features <- function(id){
print(id)
# Évitons de se faire kicker par l'API Spotify
Sys.sleep(0.1)
api_res <- GET(glue("https://api.spotify.com/v1/audio-features/{id}"), config(token = access_token))
res <- api_res$content %>%
rawToChar() %>%
fromJSON(flatten = TRUE)
tibble(danceability = res$danceability %||% NA,
energy = res$energy %||% NA,
key = res$key %||% NA,
loudness = res$loudness %||% NA,
mode = res$mode %||% NA,
speechiness = res$speechiness %||% NA,
acousticness = res$acousticness %||% NA,
instrumentalness = res$instrumentalness %||% NA,
liveness = res$liveness %||% NA,
valence = res$valence %||% NA,
tempo = res$tempo %||% NA,
type = res$type %||% NA,
id = res$id %||% NA,
uri = res$uri %||% NA,
track_href = res$track_href %||% NA,
analysis_url = res$analysis_url %||% NA,
duration_ms = res$duration_ms %||% NA,
time_signature = res$time_signature %||% NA
)
}
tracks_features <- map_df(colin_tracks$track_uri, track_features)
Et nous voici donc avec deux tables contenant les tracks de la bibliothèque. On va commencer par s'en faire un bon gros tableau :
full_tracks <- full_join(colin_tracks, tracks_features, by = c("track_uri" = "id"))
Le tableau complet fait donc 2367 morceaux, sur 26 variables, qui contiennent notamment : le nom du morceau, l'album et l'artiste, un score de confiance sur l'"acousticness", un score de dançabilité, la durée, un score d'énergie, un score prédit sur la présence ou non de chant, la tonalité, un score de présence ou non d'une audience (en gros, si c'est en concert ou non), la "loudness" du morceau, son mode (majeur == 1 ou mineur == 0), la présence de mot parlé, le tempo, le nombre de mesures, et la valence, qui est un calcul de la "positivité" du morceau : plus le score est proche de 1, plus le morceau est considéré comme positif. Débarrassons-nous des colonnes superflues :
full_tracks %<>% select(-matches("id|uri|type|hre|url|duration_ms"))
Analyse factorielle
Partons sur une rapide analyse en composante principale, afin de déterminer quelles sont les variables qui décrivent le mieux le jeu de données.
library(FactoMineR)
res_pca <- PCA(full_tracks, quali.sup = 1:3, quanti.sup = 5:6)
res_pca$eig
eigenvalue percentage of variance cumulative percentage of variance
comp 1 2.8598390 21.9987616 21.99876
comp 2 1.8598677 14.3066749 36.30544
comp 3 1.2468081 9.5908313 45.89627
comp 4 1.1089244 8.5301874 54.42646
comp 5 1.0198197 7.8447671 62.27122
comp 6 0.9280408 7.1387757 69.41000
comp 7 0.8788716 6.7605510 76.17055
comp 8 0.8434598 6.4881520 82.65870
comp 9 0.7605218 5.8501676 88.50887
comp 10 0.7124319 5.4802456 93.98911
comp 11 0.3712415 2.8557038 96.84482
comp 12 0.2803237 2.1563360 99.00115
comp 13 0.1298500 0.9988463 100.00000
 Donc, 50% de l'information expliquée par les quatre premières dimensions. Si l'on en croit le cercle des corrélations du premier pan, valence et danceability sont corrélées, tout comme loudness et energy (ce qui fait sens, n'est-ce pas ?) et duration et instrumentalness : ça, il fallait s'y attendre, les tracks les plus longues sont souvent instrumentales. Pas grand-chose à dire sur key, tempo et liveness, qui sont mal projetés sur notre premier plan. Quant à acousticness, cette variable est corrélée négativement à loudness et energy. Mais ça aussi, il fallait s'y attendre 🙂
Donc, 50% de l'information expliquée par les quatre premières dimensions. Si l'on en croit le cercle des corrélations du premier pan, valence et danceability sont corrélées, tout comme loudness et energy (ce qui fait sens, n'est-ce pas ?) et duration et instrumentalness : ça, il fallait s'y attendre, les tracks les plus longues sont souvent instrumentales. Pas grand-chose à dire sur key, tempo et liveness, qui sont mal projetés sur notre premier plan. Quant à acousticness, cette variable est corrélée négativement à loudness et energy. Mais ça aussi, il fallait s'y attendre 🙂
Quelles sont les contributions des variables à la construction des axes ?
res_pca$var$contrib
duration 0.061557070 8.51433464 17.704493327 3.1881352 15.79235016
danceability 4.832994227 25.13234108 4.825060423 0.5035654 2.11311954
energy 30.381631436 0.64333948 0.002877914 0.7775590 0.11330155
key 0.073595128 0.05875634 23.343938164 15.7110560 8.71748423
loudness 25.677788989 2.51663911 0.008358477 0.1136058 0.06260330
mode 0.066270264 0.67636383 28.394470066 17.9258895 0.65408755
speechiness 6.050315299 0.95446561 0.027011474 12.0799400 0.06130865
acousticness 25.412407378 1.26497762 1.408168526 2.1828277 0.87210617
instrumentalness 0.008530238 20.48293565 2.794116204 8.6859354 1.08643982
liveness 2.488517168 0.69130229 13.890997842 23.4841748 0.08728705
valence 2.214334583 33.55688478 0.283437162 2.6512231 0.67163776
tempo 2.653385662 0.15222361 4.845549398 12.0540043 31.57206854
time_signature 0.078672559 5.35543597 2.471521022 0.6420838 38.19620568
Nous avons un jeu de données avec 2367 observations… En clair, difficile de lire le graphe des individus. Petit tour donc du côté des résultats de la PCA :
dim1 <- res_pca$ind$contrib %>%
as.data.frame() %>%
mutate(indiv = row.names(.)) %>%
arrange(desc(Dim.1)) %>%
top_n(5, Dim.1)
dim1
Dim.1 Dim.2 Dim.3 Dim.4 Dim.5 indiv
1 0.5576816 0.30118126 0.034780033 0.0162052826 0.03300476161 1269
2 0.4899255 0.21291438 0.008330373 0.0315234685 0.00000120409 1274
3 0.4786848 0.37989445 0.010499758 0.0164488273 0.00996510231 912
4 0.4775598 0.53584278 0.014363688 0.0006587940 0.10468518176 897
5 0.4633826 0.08630106 0.058267384 0.0001801211 0.08943254035 1865
dim2 <- res_pca$ind$contrib %>%
as.data.frame() %>%
mutate(indiv = row.names(.)) %>%
arrange(desc(Dim.2)) %>%
top_n(5, Dim.2)
dim2
Dim.1 Dim.2 Dim.3 Dim.4 Dim.5 indiv
1 0.200604880 0.6177477 0.4459632115 0.050470953 0.426768240 924
2 0.477559778 0.5358428 0.0143636880 0.000658794 0.104685182 897
3 0.001126611 0.5203046 0.2807840462 0.100882448 0.016343561 74
4 0.157530632 0.5153425 0.1705381199 0.004767181 0.246680651 918
5 0.387565069 0.3940052 0.0006005656 0.021397267 0.009522307 911
indiv <- c(dim1$indiv, dim2$indiv)
Voici donc les morceaux qui contribuent le plus à la formation du plan :
full_tracks %>%
mutate(individus = row.names(.)) %>%
filter(individus %in% indiv) %>%
select(track, artist)
# A tibble: 9 x 2
track artist
1 Spirit of the North Eldamar
2 Piano Concerto In G Major, M. 83: 2. Adagio assai Maurice Ravel
3 Sonata No. 2, Op. 36: II. Non Allegro Hélène Grimaud
4 Pictures at an Exhibition: 2. The Old Castle/Il vecchio castello Sir Simon Rattle
5 Wagner: Tannhäuser, WWV 70: Overture (Andante maestoso - Allegro - Tempo primo) Richard Wagner
6 Le sacre du printemps (The Rite of Spring) (1943 version): Part 2: Le sacrifice Igor Stravinsky
7 Finding It There Goldmund
8 Ouendake Goldmund
9 Carved Tree Inn Bjorn Eriksson
Statistiques
On a écrit juste au-dessus que certaines variables étaient corrélées les unes aux autres sur le plan factoriel. Testons-le de manière un peu "old school" :
library(broom)
calls <- list(cor.test(full_tracks$danceability, full_tracks$valence),
cor.test(full_tracks$loudness, full_tracks$energy),
cor.test(full_tracks$duration, full_tracks$instrumentalness))
map_df(calls, ~ tidy(.x) %>% select(estimate, p.value, conf.low, conf.high, alternative))
estimate p.value conf.low conf.high alternative
1 0.5660656 2.139758e-200 0.5380291 0.5928511 two.sided
2 0.8175519 0.000000e+00 0.8037366 0.8304861 two.sided
3 0.1934783 2.140058e-21 0.1543925 0.2319594 two.sided
Bon, il semblerait que la corrélation se vérifie 🙂
Passons maintenant à quelques régressions. Par exemple, la variable "explicite" est-elle liée à d'autres variables du jeu de données ?
data_glm <- full_tracks %>%
select(duration:time_signature) %>%
mutate(explicit = as.numeric(explicit))
model <- glm(explicit ~ ., data = data_glm)
# Parce qu'on aime bien les jolies sorties
tidy_and_slice <- function(x, digits = 2){
tidy(x) %>%
slice(2:n()) %>%
mutate(RR = exp(estimate)) %>%
mutate_at(.vars = vars(estimate, std.error, statistic, RR), .funs = round, digits = 3) %>%
select(term, statistic, p.value, RR)
}
tidy_and_slice(model) %>%
filter(p.value < 0.05)
# A tibble: 6 x 4
term statistic p.value RR
1 popularity 5.275 1.449550e-07 1.002
2 danceability 3.836 1.283798e-04 1.159
3 loudness 3.332 8.743460e-04 1.007
4 speechiness 8.513 2.966253e-17 1.946
5 liveness 2.731 6.369635e-03 1.086
6 valence -3.324 9.019833e-04 0.912
Effectivement. On voit par exemple que pour chaque augmentation d'une unité de la variable popularity, le risque d'être classé en explicit est multiplié par 1.002. Les chansons très populaires seraient-elles plus explicites ?
ggplot(full_tracks, aes(popularity, fill = explicit)) +
geom_density() +
scale_fill_manual(values = sample(palette, 2)) +
facet_grid(explicit ~ .) +
labs(title = "Popularité et chanson 'explicit'",
subtitle = "données via Spotify",
x = "Popularité",
y = "Densité",
caption = "thinkr.fr") +
theme_few()
 Bien, cela ne saute pas aux yeux, mais on décèle quelque chose. Nous avons également vu que pour chaque augmentation d'une unité de loudness, les chances d'appartenir à la classe explicit sont multipliées par 1.007.
Bien, cela ne saute pas aux yeux, mais on décèle quelque chose. Nous avons également vu que pour chaque augmentation d'une unité de loudness, les chances d'appartenir à la classe explicit sont multipliées par 1.007.
ggplot(full_tracks, aes(loudness, fill = explicit)) +
geom_density() +
scale_fill_manual(values = sample(palette, 2)) +
facet_grid(explicit ~ .) +
labs(title = "Loudness et chanson 'explicit'",
subtitle = "données via Spotify",
x = "Loudness",
y = "Densité",
caption = "thinkr.fr") +
theme_few()
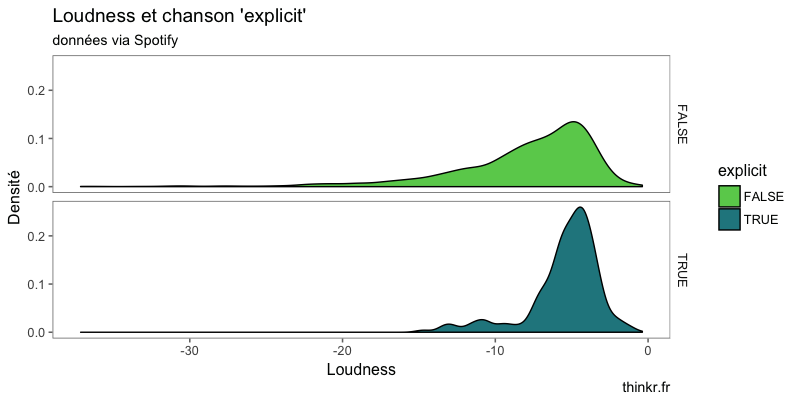 Il semblerait que les morceaux explicits soient plus concentrés vers les valeurs hautes de loudness !
Il semblerait que les morceaux explicits soient plus concentrés vers les valeurs hautes de loudness !
Aller, une petite régression linéaire pour le fun ?
modelm <- lm(energy ~ loudness, data = full_tracks)
summary(modelm)$r.squared
[1] 0.6683911
Pas trop mal. Ça donne quoi sur un graphe ?
ggplot(train, aes(energy, loudness)) +
geom_point(color = sample(palette, 1)) +
geom_smooth(method = "lm") +
labs(title = "Energy et loudness",
subtitle = "données via Spotify",
x = "Energy",
y = "loudness",
caption = "thinkr.fr") +
theme_few()
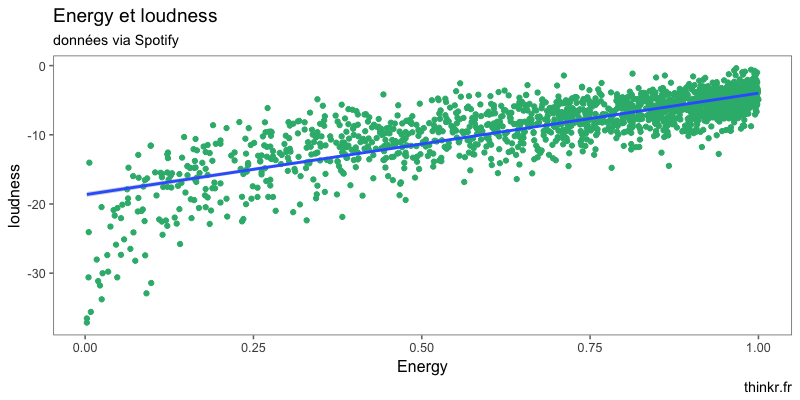 Oui, bon, il y a quelque chose, effectivement !
Oui, bon, il y a quelque chose, effectivement !
Text-mining
Et pour terminer, amusons nous avec un peu de text-mining sur le nom des morceaux. Première étape : quels sont les termes les plus fréquents ?
library(tidytext)
library(proustr)
# On va créer un seul tableau qui enlève les stop_word anglais, français, et les chiffres
stopwordsfull <- rbind(stop_words[,1],
data.frame(word = as.character(1:2017)),
proustr::proust_stopwords())
mono <- full_tracks %>%
unnest_tokens(word, track) %>%
# On stemme
pr_stem_words(word, language = "english") %>%
# On compte
count(word) %>%
# Bye bye stopwords
anti_join(stopwordsfull) %>%
# On ne garde que les 15 premiers
top_n(15, n) %>%
arrange(desc(n))
mono
# A tibble: 15 x 2
word n
1 remast 188
2 version 148
3 live 77
4 love 34
5 remix 34
6 feat 28
7 singl 27
8 hate 24
9 black 23
10 digit 23
11 danc 22
12 mix 22
13 world 22
14 blue 20
15 dead 20
Partons voir du côté des bigrams :
bi <- full_tracks %>%
select(track) %>%
unnest_tokens(word, track, token = "ngrams", n = 2) %>%
separate(word, c("word1", "word2"), sep = " ") %>%
filter(!word1 %in% stopwordsfull$word) %>%
filter(!word2 %in% stopwordsfull$word) %>%
# On stemme
pr_stem_words(word1, language = "english") %>%
pr_stem_words(word2, language = "english") %>%
unite(word, word1, word2, sep = " ") %>%
# On compte
count(word) %>%
# On ne garde que les 10 premiers
top_n(10, n) %>%
arrange(desc(n))
bi
# A tibble: 10 x 2
word n
1 remast version 90
2 singl version 21
3 digit remast 16
4 live version 16
5 live wacken 14
6 london union 12
7 union live 12
8 bonus track 10
9 radio edit 7
10 live bonus 6
Et un peu de topic modeling pour voir ?
dtm <- full_tracks %>%
unnest_tokens(word, track) %>%
# On compte
count(word, artist) %>%
# Bye bye stopwords
anti_join(stopwordsfull) %>%
cast_dtm(artist, term = word, value = n)
library(topicmodels)
lda_model <- LDA(x = dtm, k = 6, control = list(seed = 2811))
# Quels sont les individus les plus représentatifs de chaque topic ?
tidy(lda_model, matrix = "gamma") %>%
group_by(topic) %>%
arrange(desc(gamma)) %>%
top_n(1) %>%
arrange(topic)
# A tibble: 6 x 3
# Groups: topic [6]
document topic gamma
1 Hubert Félix Thiéfaine 1 0.9966540
2 Kreator 2 0.9983608
3 David Bowie 3 0.9992388
4 Terror 4 0.9949339
5 The Broken Circle Breakdown Bluegrass Band 5 0.9933348
6 Orelsan 6 0.9938862
Un partitionnement qui, à première vue, semble faire sens 😉 Et si on visualise les topics ?
tidy(lda_model, matrix = "beta") %>%
group_by(topic) %>%
top_n(10, beta) %>%
ungroup() %>%
arrange(topic, -beta) %>%
ggplot(aes(reorder(term, beta), beta, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
scale_fill_manual(values = sample(palette)) +
coord_flip() +
labs(x = "Topic",
y = "beta score",
subtitle = "données via Spotify",
caption = "thinkr.fr") +
theme_few()
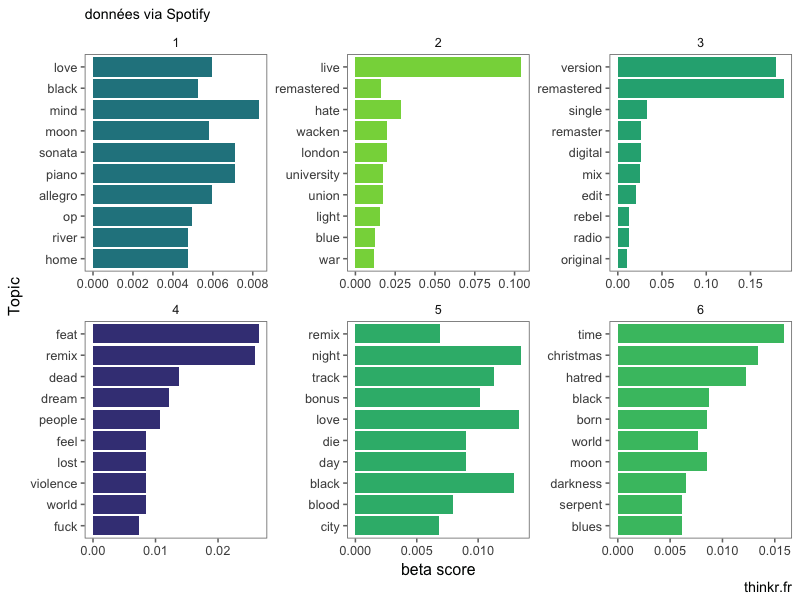 On voit que les topics couvrent des sujets parfois... différents. Le premier topic mixe "love" et "black" avec des termes plutôt liés au classique (allegro, sonata, piano). Le topic 3 paraît plus unifié, avec des termes autour de "version", "remastered", "single", caractéristique de la définition des conditions d'enregistrement des morceaux.
On voit que les topics couvrent des sujets parfois... différents. Le premier topic mixe "love" et "black" avec des termes plutôt liés au classique (allegro, sonata, piano). Le topic 3 paraît plus unifié, avec des termes autour de "version", "remastered", "single", caractéristique de la définition des conditions d'enregistrement des morceaux.
Bon, c'était bien fun tout ça ! Vivement la prochaine !



[…] connecter à Spotify, on l’a déjà fait, on ne va pas vous en reparler […]